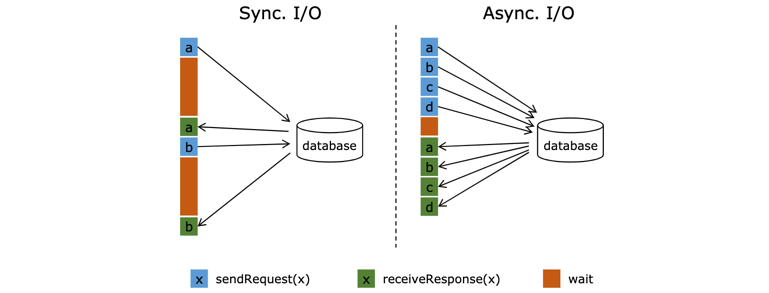
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
| package com.bigdata.flink;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.google.common.cache.Cache;
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.RemovalListener;
import com.google.common.cache.RemovalNotification;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.tuple.Tuple5;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.action.ActionListener;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.util.Collections;
import java.util.concurrent.TimeUnit;
public class ElasticsearchAsyncFunction extends RichAsyncFunction<Tuple4<String, String, String, Integer>, Tuple5<String, String, String, Integer,Integer>> {
private String host;
private Integer port;
private String user;
private String password;
private String index;
private String type;
public ElasticsearchAsyncFunction(String host, Integer port, String user, String password, String index, String type) {
this.host = host;
this.port = port;
this.user = user;
this.password = password;
this.index = index;
this.type = type;
}
private RestHighLevelClient restHighLevelClient;
private Cache<String,Integer> cache;
@Override
public void open(Configuration parameters){
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(user, password));
restHighLevelClient = new RestHighLevelClient(
RestClient
.builder(new HttpHost(host, port))
.setHttpClientConfigCallback(httpAsyncClientBuilder -> httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider)));
cache=CacheBuilder.newBuilder().maximumSize(2).expireAfterAccess(5, TimeUnit.MINUTES).build();
}
@Override
public void close() throws Exception {
restHighLevelClient.close();
}
@Override
public void asyncInvoke(Tuple4<String, String, String, Integer> input, ResultFuture<Tuple5<String, String, String, Integer, Integer>> resultFuture) {
Integer cachedValue = cache.getIfPresent(input.f0);
if(cachedValue !=null){
System.out.println("从缓存中获取到维度数据: key="+input.f0+",value="+cachedValue);
resultFuture.complete(Collections.singleton(new Tuple5<>(input.f0,input.f1,input.f2,input.f3,cachedValue)));
}else {
searchFromES(input,resultFuture);
}
}
private void searchFromES(Tuple4<String, String, String, Integer> input, ResultFuture<Tuple5<String, String, String, Integer, Integer>> resultFuture){
Tuple5<String, String, String, Integer, Integer> output = new Tuple5<>();
output.f0=input.f0;
output.f1=input.f1;
output.f2=input.f2;
output.f3=input.f3;
String dimKey = input.f0;
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(index);
searchRequest.types(type);
searchRequest.source(SearchSourceBuilder.searchSource().query(QueryBuilders.idsQuery().addIds(dimKey)));
restHighLevelClient.searchAsync(searchRequest, new ActionListener<SearchResponse>() {
@Override
public void onResponse(SearchResponse searchResponse) {
SearchHit[] searchHits = searchResponse.getHits().getHits();
if(searchHits.length >0 ){
JSONObject obj = JSON.parseObject(searchHits[0].getSourceAsString());
Integer dimValue=obj.getInteger("age");
output.f4=dimValue;
cache.put(dimKey,dimValue);
System.out.println("将维度数据放入缓存: key="+dimKey+",value="+dimValue);
}
resultFuture.complete(Collections.singleton(output));
}
@Override
public void onFailure(Exception e) {
output.f4=null;
resultFuture.complete(Collections.singleton(output));
}
});
}
@Override
public void timeout(Tuple4<String, String, String, Integer> input, ResultFuture<Tuple5<String, String, String, Integer, Integer>> resultFuture) {
searchFromES(input,resultFuture);
}
}
|