CANAL源码解析-filter模块
Filter简介
filter模块用于对binlog进行过滤。在实际开发中,一个mysql实例中可能会有多个库,每个库里面又会有多个表,可能我们只是想订阅某个库中的部分表,这个时候就需要进行过滤。也就是说,parser模块解析出来binlog之后,会进行一次过滤之后,才会存储到store模块中。
过滤规则的配置既可以在canal服务端进行,也可以在客户端进行。
服务端配置
我们在配置一个canal instance时,在instance.properties中有以下两个配置项:

其中:
- canal.instance.filter.regex用于配置白名单,也就是我们希望订阅哪些库,哪些表,默认值为.\..,也就是订阅所有库,所有表。
- canal.instance.filter.black.regex用于配置黑名单,也就是我们不希望订阅哪些库,哪些表。没有默认值,也就是默认黑名单为空。
需要注意的是,在过滤的时候,会先根据白名单进行过滤,再根据黑名单过滤。意味着,如果一张表在白名单和黑名单中都出现了,那么这张表最终不会被订阅到,因为白名单通过后,黑名单又将这张表给过滤掉了。
另外一点值得注意的是,过滤规则使用的是perl正则表达式,而不是jdk自带的正则表达式。意味着filter模块引入了其他依赖,来进行匹配。具体来说,filter模块的pom.xml中包含以下两个依赖:
1 | <dependency> |
其中:
- aviator:是一个开源的、高性能、轻量级的 java 语言实现的表达式求值引擎
- oro: 全称为Jakarta ORO,最全面以及优化得最好的正则表达式API之一,Jakarta-ORO库以前叫做OROMatcher,是由DanielF. Savarese编写,后来捐赠给了apache Jakarta Project。canal的过滤规则就是通过oro中的Perl5Matcher来进行完成的。
显然,对于filter模块的源码解析,实际上主要变成了对aviator、oro的分析。
这一点,我们可以从filter模块核心接口CanalEventFilter的实现类中得到验证。CanalEventFilter接口定义了一个filter方法:
1 | public interface CanalEventFilter<T> { |
目前针对CanalEventFilter提供了3个实现类,都是基于开源的java表达式求值引擎Aviator,如下:
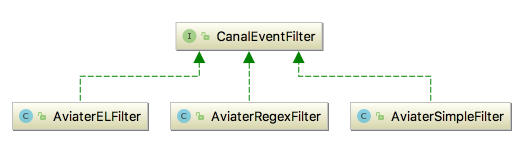
提示:这个3个实现都是以Aviater开头,应该是拼写错误,正确的应该是Aviator。
其中:
- AviaterELFilter:基于Aviator el表达式的匹配过滤
- AviaterSimpleFilter:基于Aviator进行tableName简单过滤计算,不支持正则匹配
- AviaterRegexFilter:基于Aviator进行tableName正则匹配的过滤算法。内部使用到了一个RegexFunction类,这是对Aviator自定义的函数的扩展,内部使用到了oro中的Perl5Matcher来进行正则匹配。
需要注意的是,尽管filter模块提供了3个基于Aviator的过滤器实现,但是实际上使用到的只有AviaterRegexFilter。这一点可以在canal-deploy模块提供的xxx-instance.xml配置文件中得要验证。以default-instance.xml为例,eventParser这个bean包含以下两个属性:
其中:
- eventFilter属性:使用配置项canal.instance.filter.regex的值进行白名单过滤。
- eventBlackFilter属性:使用配置项canal.instance.filter.black.regex进行黑名单过滤。
这两个属性的值都是通过一个内部bean的方式进行配置,类型都是AviaterRegexFilter。由于其他两个类型的CanalEventFilter实现在parser模块中并没有使用到,因此后文中,我们也只会对AviaterRegexFilter进行分析。
前面提到,parser模块在过滤的时候,会先根据canal.instance.filter.regex进行白名单过滤,再根据 canal.instance.filter.black.regex进行黑名单过滤。到这里,实际上就是先通过eventFilter进行白名单过滤,通过eventBlackFilter进行黑名单过滤。
parser模块实际上会将eventFilter、eventBlackFilter设置到一个LogEventConvert对象中,这个对象有2个方法:parseQueryEvent和parseRowsEvent都进行了过滤。以parseRowsEvent方法为例:
com.alibaba.otter.canal.parse.inbound.mysql.dbsync.LogEventConvert#parseRowsEvent(省略部分代码片段)
1 | private Entry parseRowsEvent(RowsLogEvent event) { |
这里的nameFilter、nameBlackFilter实际上就是我们设置到parser中的 eventFilter、eventBlackFilter,只不过parser将其设置到LogEventConvert对象中换了一个名字。
可以看到,的确是先使用nameFilter进行白名单过滤,再使用nameBlackFilter进行黑名单过滤。在过滤时,使用dbName+”.”+tableName作为参数,进行过滤。如果被过滤掉了,就返回null。
再次提醒,由于黑名单后过滤,因此如果希望订阅一个表,一定不要在黑名单中出现。
客户端配置
上面提到的都是服务端配置。canal也支持客户端配置过滤规则。举例来说,假设一个库有10张表,一个client希望订阅其中5张表,另一个client希望订阅另5张表。此时,服务端可以订阅10张表,当client来消费的时候,根据client的过滤规则只返回给对应的binlog event。
客户端指定过滤规则通过client模块中的CanalConnector的subscribe方法来进行,subscribe有两种重载形式,如下:
1 | //对于第一个subscribe方法,不指定filter,以服务端的filter为准 |
通过不同client指定不同的过滤规则,可以达到服务端一份数据供多个client进行订阅消费的效果。
然而,想法是好的,现实确是残酷的,由于目前一个canal instance只允许一个client订阅,因此目前还达不到这种效果。读者明白这种设计的初衷即可。
最后列出filter模块的目录结构,这个模块的类相当的少,如下:
到此,filter模块的主要作用已经讲解完成。接着应该针对AviaterRegexFilter进行源码分析,由于其基于Aviator和oro基础之上编写,因此先对Aviator和oro进行介绍。
Aviator快速入门
说明,这里关于Aviator的相关内容直接摘录自官网:https://github.com/killme2008/aviator, 并没有包含Aviator所有内容,仅仅是就canal内部使用到的一些特性进行讲解。
Aviator是一个高性能、轻量级的 java 语言实现的表达式求值引擎, 主要用于各种表达式的动态求值。现在已经有很多开源可用的 java 表达式求值引擎,为什么还需要 Avaitor 呢?
Aviator的设计目标是轻量级和高性能,相比于Groovy、JRuby的笨重, Aviator非常小, 加上依赖包也才 537K,不算依赖包的话只有 70K; 当然, Aviator的语法是受限的, 它不是一门完整的语言, 而只是语言的一小部分集合。
其次, Aviator的实现思路与其他轻量级的求值器很不相同, 其他求值器一般都是通过解释的方式运行, 而Aviator则是直接将表达式编译成 JVM 字节码, 交给 JVM 去执行。简单来说, Aviator的定位是介于 Groovy 这样的重量级脚本语言和 IKExpression 这样的轻量级表达式引擎之间。
Aviator 的特性:
- 支持绝大多数运算操作符,包括算术操作符、关系运算符、逻辑操作符、位运算符、正则匹配操作符(=~)、三元表达式(?:)
- 支持操作符优先级和括号强制设定优先级
- 逻辑运算符支持短路运算。
- 支持丰富类型,例如nil、整数和浮点数、字符串、正则表达式、日期、变量等,支持自动类型转换。
- 内置一套强大的常用函数库
- 可自定义函数,易于扩展
- 可重载操作符
- 支持大数运算(BigInteger)和高精度运算(BigDecimal)
- 性能优秀
引入Aviator, 从 3.2.0 版本开始, Aviator 仅支持 JDK 7 及其以上版本。 JDK 6 请使用 3.1.1 这个稳定版本。
1 | <dependency> |
Aviator的使用都是集中通过com.googlecode.aviator.AviatorEvaluator这个入口类来处理。在canal提供的AviaterRegexFilter中,仅仅使用到了Aviator部分功能,我们这里也仅仅就这些功能进行讲解。
编译表达式
案例:
1 | public class TestAviator { |
通过compile方法可以将表达式编译成Expression的中间对象, 当要执行表达式的时候传入env并调用Expression的execute方法即可。 表达式中使用了括号来强制优先级, 这个例子还使用了>用于比较数值大小, 比较运算符!=、==、>、>=、<、<=不仅可以用于数值, 也可以用于String、Pattern、Boolean等等, 甚至是任何用户传入的两个都实现了java.lang.Comparable接口的对象之间。
编译后的结果你可以自己缓存, 也可以交给 Aviator 帮你缓存, AviatorEvaluator内部有一个全局的缓存池, 如果你决定缓存编译结果, 可以通过:1
public static Expression compile(String expression, boolean cached)
将cached设置为true即可, 那么下次编译同一个表达式的时候将直接返回上一次编译的结果。
使缓存失效通过以下方法:
1 | public static void invalidateCache(String expression) |
自定义函数
Aviator 除了内置的函数之外,还允许用户自定义函数,只要实现com.googlecode.aviator.runtime.type.AviatorFunction接口, 并注册到AviatorEvaluator即可使用. AviatorFunction接口十分庞大, 通常来说你并不需要实现所有的方法, 只要根据你的方法的参 数个数, 继承AbstractFunction类并override相应方法即可。
可以看一个例子,我们实现一个add函数来做数值的相加:
1 | //1、自定义函数AddFunction,继承AbstractFunction,覆盖其getName方法和call方法 |
注册函数通过AviatorEvaluator.addFunction方法, 移除可以通过removeFunction。另外, FunctionUtils 提供了一些方便参数类型转换的方法。
AviaterRegexFilter源码解析
AviaterRegexFilter实现了CanalEventParser接口,主要是实现其filter方法对binlog进行过滤。
首先对AviaterRegexFilter中定义的字段和构造方法进行介绍:
com.alibaba.otter.canal.filter.aviater.AviaterRegexFilter
1 | public class AviaterRegexFilter implements CanalEventFilter<String> { |
上述代码中,2.2 步骤使用了COMPARATOR对list中分割后的pattern进行比较,COMPARATOR的类型是StringComparator,这是定义在AviaterRegexFilter中的一个静态内部类
1 | /** |
上述代码2.3节调用completionPattern(list)方法对list中分割后的pattern进行头尾完全匹配
1 | /** |
filter方法
AviaterRegexFilter类中最重要的就是filter方法,由这个方法执行过滤,如下:
1 | //1 参数:前面已经分析过parser模块的LogEventConvert中,会将binlog event的 dbName+”."+tableName当做参数过滤 |
第4步通过exp.execute方法进行过滤判断,前面已经看到,exp这个Expression实例是通过”regex(pattern,target)”编译得到。根据前面对AviatorEvaluator的介绍,其应该调用一个名字为regex的Aviator自定义函数,这个函数接受2个参数。
RegexFunction的实现如下所示:
1 | public class RegexFunction extends AbstractFunction { |
可以看到,在这个函数里面,实际上是根据配置的过滤规则pattern,以及需要过滤的内容text(即dbName+”.”+tableName),通过jarkata-oro中Perl5Matcher类进行正则表达式匹配。