CANAL源码解析-binlog消费位点的控制
文章目录
canal是一个订阅消费模式的服务,于是其消费位点的控制就非常重要,在正常情况或者重启canal之后都要保证不重复消费同一个位点,也不能漏掉某一个位点。本文我们来看看canal是如何控制消费位点的。
首先我们来分析客户端是如何工作,前文我们分析过CanalMQStarter的启动过程会为每个destination都新建一个CanalMQRunnable,在不同的线程中来执行CanalMQRunnable。CanalMQRunnable的执行调用CanalMQStarter的worker方法。数据的消费与传输都在这个worker方法中执行。
CanalMQStarter.work
首先是一个准备过程:
- 新建ClientIdentity,作为client的标识
- 从canalServer(
CanalServerWithEmbedded)中获取instance - 新建
CanalDestination,这个类保存了mq的配置信息 - 调用
canalServer.subscribe向CanalServerWithEmbedded中注册client的信息
a. 调用checkStart确保destination对应的instance已经启动
b. 获取instance中保存的CanalMetaManager,CanalMetaManager是meta信息的管理器,其中保存着关键的position信息
c. 判断CanalMetaManager是否已经启动,如果没有启动则调用start()方法启动CanalMetaManager。正常情况下CanalMetaManager在instance启动时已经被启动了
d. 调用CanalMetaManager的subscribe方法在CanalMetaManager中增加订阅信息
e. 调用CanalMetaManager的getCursor方法获取当前订阅binlog的位置信息
f. 如果position为null,说明之前没有记录position信息:
g. 调用- 从`CanalEventStore`中获取保存的第一条数据的position信息 - 如果`CanalEventStore`中保存的position信息不为null,调用`CanalMetaManager`的`updateCursor`方法更新`CanalMetaManager`中保存的position信息CanalInstance的subscribeChange方法,通知CanalInstance订阅关系变化- 如果identity中设置的filter过滤条件不为空,则将其设置到eventParser中
前面的准备过程基本就是一个向CanalMetaManager注册客户端并处理消费位点的工作。
接下来是循环读取数据的过程:
- 调用
CanalServerWithEmbedded的getWithoutAck方法获取binlog消息。getWithoutAck方法一次获取一批(batch)的binlog,canal会为这批binlog生成一个唯一的batchId。客户端如果消费成功,则调用ack方法对这个批次的数据进行确认。如果失败的话,可以调用rollback方法进行回滚。客户端可以连续多次调用getWithoutAck方法来获取binlog,在ack的时候,需要按照获取到binlog的先后顺序进行ack。如果后面获取的binlog被ack了,那么之前没有ack的binlog消息也会自动被ack。
注意getWithoutAck方法中有一个synchronized (canalInstance)代码,即虽然destination可以对应多个客户端,但是每个客户端不能并发获取binlog消息。
1. 从`CanalEventStore`中读取数据,保存在events中:
a. 如果`PositionRange`不为null,从CanalEventStore中获取PositionRange开始位置之后的数据
b. 如果`PositionRange`为null,说明是ack后第一次获取数据:
- 调用`CanalMetaManager`的getCursor(ClientIdentity clientIdentity)方法获取cursor游标start。如果start为null,调用`CanalEventStore`的getFirstPosition方法获取CanalEventStore中保存的第一条数据
- 从`CanalEventStore`中获取start之后的数据
c. 将events包装成Message返回:
- 如果events为空,返回空的Message,batchId设置为-1。
- 果events不为空,调用`CanalMetaManager`的`addBatch`方法记录`PositionRange`,返回一个唯一的batchId。将events做相应转换之后包装成Message返回。
根据位置从`CanalEventStore`中获取binlog数据,为了尽量提高效率,一般一次获取一批binlog,而不是获取一条。这个批次的大小(batchSize)由客户端指定。同时客户端可以指定超时时间,在超时时间内,如果获取到了batchSize的binlog,会立即返回。如果超时了还没有获取到batchSize指定的binlog个数,也会立即返回。特别的,如果没有设置超时时间,没有获取到binlog也会立即返回。
在`CanalMetaManager`中记录这个批次的binlog消息。`CanalMetaManager`会为获取到的这个批次的binlog生成一个唯一的batchId。batchId是递增的,如果binlog信息为空,则直接把batchId设置为-1。
如果message不为空,将数据发送到mq中
如果发送成功,调用CanalServerWithEmbedded的ack方法确认小于batchId的消息已经被消费。
a. 调用CanalMetaManager的removeBatch删除batchId表示的PositionRange数据
b. 调用CanalMetaManager的updateCursor方法更新cursor
c. 调用CanalEventStore的ack方法删除经过确认的数据如果发送失败,调用CanalServerWithEmbedded的rollback方法回滚batchId表示的数据
a. 调用CanalMetaManager的removeBatch删除batchId表示的PositionRange数据
b. 调用CanalEventStore的rollback方法回滚到指定的位置
下面我们来分析其中涉及到的细节。
CanalMetaManager
从前面的分析中,消费位点控制最关键的是CanalMetaManager类。CanalMetaManager主要用于记录客户端获取的未ack的PositionRange日志信息(开始位置、结束位置、ack位置以及对应的batchId),实现重试功能,保证数据传输的可靠性。提供如下功能:
- 订阅行为处理:记录destination和ClientIdentity的对应关系
- 未ack日志记录行为处理:通过MemoryClientIdentityBatch来实现获取指定batchId、最新或者第一个未ack日志的PositionRange。
- 添加、获取未ack的日志记录:通过从eventstore中获取指定数量的event的PositionRange后(并不保存数据信息),添加到CanalMetaManager中,并通过唯一batchId进行绑定,支持通过batchId获取未ack日志记录的功能。
- 删除已经ack日志记录的行为:通过batchId删除已经ack过的日志记录。注意:ack和rollback必须按照分发处理的顺序处理,即只能ack当前最小的batchId。不然容易出现丢数据的问题。
- 获取、清空所有未处理ack日志:获取和清空MemoryClientIdentityBatch中的记录
- 更新最近被ack的日志文件位置:从PositionRange中获取应该ack的Position位置,进行更新到cursor游标中
下面我们来分析CanalMetaManager类。
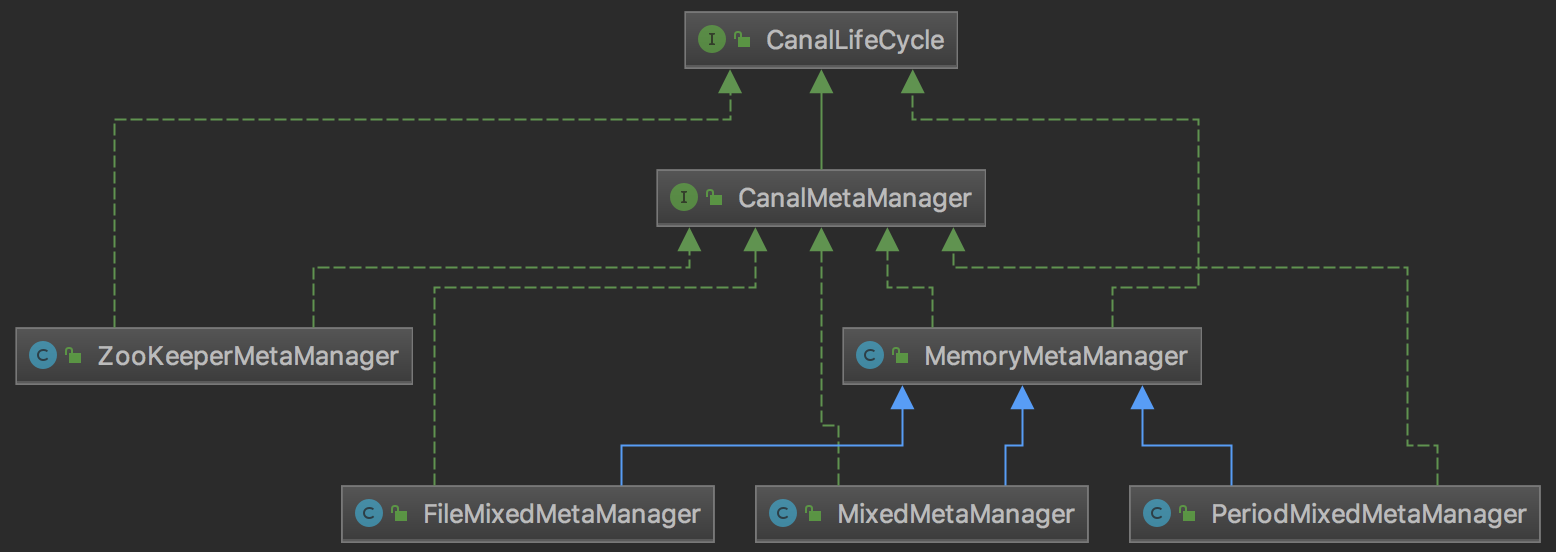
如上图所示,CanalMetaManager是一个接口,其中有5个实现类。canal是如何来选择实现类的呢?前文我们提到过canal的实例是通过Spring来生成的,生成实例配置的时候会指定xml文件,Spring就是通过这个xml文件来生成实例。
默认可以选择以下几种xml文件,后面写上了它选择的CanalMetaManager实现类:
- spring/default-instance.xml:PeriodMixedMetaManager
- spring/file-instance.xml:FileMixedMetaManager
- spring/group-instance.xml:MemoryMetaManager
- spring/memory-instance.xml:MemoryMetaManager
可以看到不同的xml配置文件,选择的CanalMetaManager实现类是不同的。其中最为重要的是MemoryMetaManager,其中几个实现类也是基于它实现的。
下面我们来分析MemoryMetaManager类。
MemoryMetaManager
如名称所示,MemoryMetaManager将日志消费位点信息记录在内存中。
它有3个变量:
1 | protected Map<String, List<ClientIdentity>> destinations; |
- destinations中保存的是每个destination对应的客户端(从中可以看出针对一个destination可以启动多个客户端)
- batches中保存的是客户端消费的log位置范围
- cursors中保存的是客户端应答后的log位置
下面说明一下其中涉及的类:
ClientIdentity:客户端的标识。其中保存着以下3个字段:
1
2
3private String destination;
private short clientId;
private String filter;
1 | `clientId`默认为`1001` |
batches中保存着batchId和PositionRange的对应关系。PositionRange中保存日志的开始位置、结束位置和ack位置。
atomicMaxBatchId记录最大的batchId。
Position:
Position是一个抽象类,其实现类LogPosition用于标识数据库日志位置。
其中保存着一下2个字段:
1 | private LogIdentity identity; |
1 | `LogIdentity`是数据库日志标识。保存着canal server的`slaveId`和`sourceAddress`信息 |
下面来分析MemoryMetaManager的几个方法:
subscribe相关的方法
subscribe相关的方法有如下4个,具体代码略
1 | /** |
主要的功能就是围绕destinations变量,在ClientIdentity列表中增减数据。本质上就是在destinations中记录ClientIdentity数据,来表示客户端正在订阅数据。删除订阅则是删除destinations中的ClientIdentity数据。
cursor相关的方法
cursor相关的方法有如下2个,具体代码略
1 | /** |
cursor相关的方法也是简单地围绕cursors记录ClientIdentity对应的Position信息。
batch相关的方法
batch相关的方法有如下8个,具体代码略
1 | /** |
这些方法获取batches中保存的MemoryClientIdentityBatch,调用MemoryClientIdentityBatch类中的相应方法:
1 | public synchronized void addPositionRange(PositionRange positionRange, Long batchId) { |
可以看到,MemoryClientIdentityBatch中方法就是围绕着batches变量对PositionRange进行增删改查。
PeriodMixedMetaManager
我们再来看看PeriodMixedMetaManager,它是default-instance.xml中定义的CanalMetaManager实现。
它和MemoryMetaManager的主要区别就是增加了一个定时任务:
1 | updateCursorTasks = Collections.synchronizedSet(new HashSet<ClientIdentity>()); |
该定时任务的主要功能就是获取内存中保存的cursor数据,将其保存到zookeeper中。当canal重启之后能获得之前已经处理过的cursor数据,canal就可以从这个位置接下去获取新的数据。
更新cursor的操作在updateCursor方法中触发:
1 | public void updateCursor(ClientIdentity clientIdentity, Position position) throws CanalMetaManagerException { |
FileMixedMetaManager
再来看看FileMixedMetaManager,它是file-instance.xml中定义的CanalMetaManager实现。
它和PeriodMixedMetaManager的主要区别就是PeriodMixedMetaManager是将cursor数据写到zookeeper,而FileMixedMetaManager是将cursor数据写到文件中,文件名为meta.dat。这种机制主要适合单机部署canal的时候使用。
1 | updateCursorTasks = Collections.synchronizedSet(new HashSet<ClientIdentity>()); |
总结
canal在CanalMetaManager中管理binlog消费位点。它的消费流程可以总结为以下几个步骤:
- 获取读取binlog的开始位置。这个开始位置依次从3个地方获取:最近的batch数据、cursor游标、CanalEventStore中保存的第一条数据
- 从CanalEventStore中获取这个上面开始位置之后的一批binlog数据,保存到CanalMetaManager的batch中,返回一个唯一的batchId
- 数据消费成功后,调用ack方法确认batchId表示的一批数据。否则调用rollback回滚batchId表示的数据