CANAL源码解析-启动流程
总体
canal的入口函数是CanalLauncher的main方法,我们来跟踪代码的执行流程。
- 加载
canal.properties。如果指定了canal.conf则使用指定的配置,否则使用默认的canal.properties文件。 - 新建
CanalStater并启动
a. 判断canal.serverMode,如果为kafka则新建CanalKafkaProducer。设置canal.withoutNetty为true,以及用户定义的canal.destinations
b. 新建CanalController
c. 调用1. 调用`initGlobalConfig`方法初始化全局参数设置 - 获取并设置`mode`,默认为`SPRING` - 获取并设置`lazy`,默认为`false` - 获取并设置`managerAddress`,默认为`null` - 取并设置`springXml`,默认为`classpath:spring/file-instance.xml` - 创建`instanceGenerator`,实例生成器。用于根据`destination`生成实例 2. 调用`initInstanceConfig`初始化实例配置 - 获取`canal.destinations`配置 - 将`canal.destinations`以,分割 - 针对每个`destination`: - 调用`parseInstanceConfig`方法解析`destination`的配置。与初始化全局参数设置类似,这里根据具体的`destination`配置`mode`、`lazy`、`managerAddress`、`springXml` - 将解析得到的`destination`配置保存在`instanceConfigs` 3. 如果配置了`canal.socketChannel`,设置`canal.socketChannel`属性 4. 如果存在的话,分别设置`canal.instance.rds.accesskey`和`canal.instance.rds.secretkey`属性 5. 获取`cid`、`ip`、`port`属性 6. 获取`embededCanalServer`,并设置`instanceGenerator`。`embededCanalServer`的类型为`CanalServerWithEmbedded` 7. 获取并设置`embededCanalServer`的`metricsPort` 8. 如果`canal.withoutNetty`为`null`或者`false`,创建`canalServer`并配置`ip`和`port`。 9. 如果`ip`属性为空,配置本机`ip` 10. 获取`canal.zkServers`,`zookeeper`的地址 - 如果`canal.zkServers`不为空,在`zookeeper`中创建`/otter/canal/destinations`和`/otter/canal/cluster`目录 11. 创建服务器运行信息`ServerRunningData` 12. 将`ServerRunningData`设置在服务器运行监控`ServerRunningMonitors`中。在`ServerRunningMonitors`中设置每个`destination`的运行监控器`ServerRunningMonitor` 13. 获取`canal.auto.scan`属性,默认为`true` - 创建`InstanceAction`,实例执行器。其中定义了实例启动、停止、重启3个操作 - 创建`InstanceConfigMonitor`,实例配置监视器。start()方法启动CanalController
d. 设置设置退出时执行的钩子线程1. `zookeeper`中创建`canal`服务器的`path`,`path`为`/otter/canal/cluster/{ip}:{port}` 2. 在`zookeeper`中创建状态变化的监听器 3. 调用`start()`方法启动`embededCanalServer` - 加载并初始化`CanalMetricsService` - 创建`canalInstances` 4. 遍历各个`instance` - 调用`ServerRunningMonitor.start()`方法启动每个`destination`的`ServerRunningMonitor` - 调用`processStart()`方法。在`zookeeper`中新建`/otter/canal/destinations/{name}/cluster/{ip}:{port}`目录,并监听`zookeeper`状态的修改 - 监听`zookeeper`中`/otter/canal/destinations/{name}/running`目录的变动 - 调用`initRunning()`方法 - 在`zookeeper`的`/otter/canal/destinations/{name}/running`目录中增加正在运行的`canal`服务器信息 - 调用`processActiveEnter`方法触发`destination`对应的`canal`实例`(CanalInstance)`开始执行 - 为每个destination注册`InstanceAction` 5. 启动实例配置的监听器`InstanceConfigMonitor` 6. 如果`canalServer`不为`null`,则调用`start()`方法启动`canalServer`。如果没有指定`mq`模式,则会启动`canalServer`。`canalServer`是使用`Netty`写的服务端,接收用户连接,发送数据。shutdownThread
e. 如果canalMQProducer不为null,新建并启动CanalMQStarter1. 设置mq的属性 2. 为每个destination新建一个`CanalMQRunnable`并启动
启动流程总结
canal的简易时序图如下所示
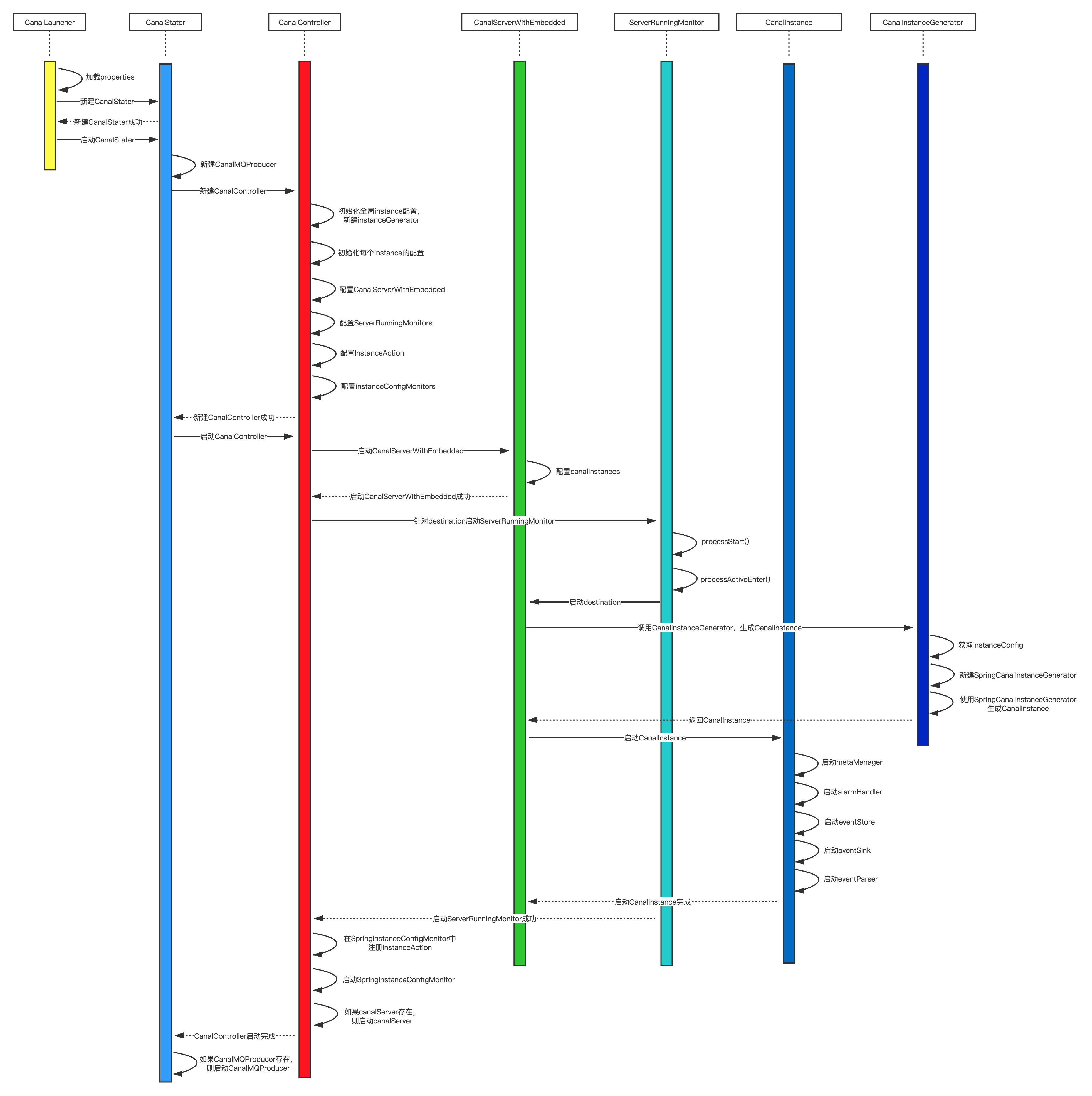
从时序图可以看出CanalController是canal启动过程中处于中心调用位置的类,负责初始化各种配置并启动CanalServerWithEmbedded。
CanalServerWithEmbedded可以看成是一个canal实例的管理容器,其中有一个Map<String, CanalInstance> canalInstances变量保存所有的canal实例,负责各个canal实例(CanalInstance)的启动。
CanalInstance是真正执行mysql日志解析的类。用户配置了多少个destinations,就会启动多少个CanalInstance。每个CanalInstance会连接mysql,dump binlog,然后将数据交给parser解析,sink过滤,store存储。接下来,我们来分析CanalInstance的执行。
CanalInstance
通过前面的启动流程知道,CanalInstance的启动流程如下:
- CanalLauncher.main()
- CanalStater.start()
- CanalController.start()
- ServerRunningMonitor.start()
- ServerRunningMonitor.initRunning()
- ServerRunningMonitor.processActiveEnter()
- CanalServerWithEmbedded.start(final String destination)
CanalServerWithEmbedded.start(final String destination)方法负责具体destination的启动:
- 从
canalInstances中获取destination对应的CanalInstance
canalInstances是一个Map,如果其中不存在对应destination的CanalInstance,调用CanalInstanceGenerator.generate(String destination)生成CanalInstance
a. 从instanceConfigs中获取相应destination的配置
b. 默认通过Spring生成Instance。- 创建`SpringCanalInstanceGenerator` - 调用`getBeanFactory(String springXml)`根据spring配置文件生成`Spring Context`。`Spring Context`中生成了几个重要的`Bean:instance`(Canal实例)、`eventParser`(解析)、`eventSink`(过滤)、`eventStore`(存储)、`metaManager`(元数据管理)、`alarmHandler`(报警) - 调用`generate(String destination)`方法从`Spring Context`中获取destination对应的`CanalInstance`。`CanalInstance`的实际类为`CanalInstanceWithSpring`。 - 调用
CanalInstance.start()方法启动Instance
a. 按先后顺序分别启动metaManager(FileMixedMetaManager)、alarmHandler(LogAlarmHandler)、eventStore(MemoryEventStoreWithBuffer)、eventSink(EntryEventSink)、eventParser(RdsBinlogEventParserProxy)。
CanalEventParser
CanalEventParser在CanalInstance启动时被启动。CanalEventParser的实际类是RdsBinlogEventParserProxy,其真正的start()方法处于父类AbstractEventParser中。启动过程完成以下三件事:
- 配置
EventTransactionBuffer - 构建
BinlogParser - 新建
ParseThread(binlog解析线程)并启动
binlog解析线程的执行
- 创建Mysql连接
- 为Mysql连接启动一个心跳
- 调用
preDump方法执行dump前的准备工作- 调用
connect()方法连接mysql - 验证Mysql中配置的binlog-format是否能被支持
- 验证Mysql中配置的binlog-image是否能被支持
- 调用
- 调用
connect()方法连接mysql - 获取
serverId - 调用
findStartPosition方法获取binlog的开始位置 - 调用
processTableMeta方法回滚到指定位点 - 调用
reconnect()方法重新链接,因为在找position过程中可能有状态,需要断开后重建 调用
MysqlConnection.dump方法dump数据- 向mysql发送更新设置的请求
- 获取binlog的checksum信息
- 向mysql注册slave信息
- 向mysql发送dump binlog的请求
接下去循环读取binlog,存储在
LogBuffer中调用
MultiStageCoprocessor.publish投递数据MultiStageCoprocessor的实际类为MysqlMultiStageCoprocessor。MysqlMultiStageCoprocessor中维护着一个disruptorMsgBuffer。disruptorMsgBuffer的类是RingBuffer,这是一个无锁队列。存储在LogBuffer中的binlog数据被投递到disruptorMsgBuffer中。MysqlMultiStageCoprocessor针对解析器提供一个多阶段协同的处理。LogBuffer被投递到disruptorMsgBuffer之后分为3个阶段被处
理:- 事件基本解析 (单线程,事件类型、DDL解析构造TableMeta、维护位点信息),调用
SimpleParserStage.onEvent处理 - 事件深度解析 (多线程, DML事件数据的完整解析),调用
DmlParserStage.onEvent处理 - 投递到store (单线程),调用
SinkStoreStage.onEvent处理SinkStoreStage.onEvent中如果event的Entry不为null,则将其添加到EventTransactionBuffer中。EventTransactionBuffer缓冲event队列,提供按事务刷新数据的机制。EventTransactionBuffer根据event调用EntryEventSink的sink方法,sink处理之后保存在MemoryEventStoreWithBuffer之中。
CanalMQProducer
经过前面的分析,我们知道了binlog经过解析、过滤等步骤之后最终被保存在MemoryEventStoreWithBuffer之中。下面我们来分析CanalMQProducer的执行。
在CanalStater的启动过程的最后,判断canalMQProducer是否为null。
如果我们设置了serverMode为kafka或者rocketmq,canalMQProducer的对象分别为CanalKafkaProducer和CanalRocketMQProducer,此时canalMQProducer不为null。于是新建CanalMQStarter,将canalMQProducer作为参数传入,然后启动CanalMQStarter。
CanalMQStarter的启动过程会为每个destination都新建一个CanalMQRunnable,每个destination都在单独的线程中执行。
CanalMQRunnable执行流程如下:
- 根据destination创建
ClientIdentity - 调用
canalServer.subscribe(clientIdentity)订阅client信息 - 循环调用
canalServer.getWithoutAck从canal中获取消息- 获取最后获取到的数据的位置
- 调用
getEvents方法获取数据。调用MemoryEventStoreWithBuffer.get,最终调用MemoryEventStoreWithBuffer.doGet方法获取保存的数据
- 调用
canalMQProducer.send向mq发送消息
总结
经过上面的分析,对canal的工作流程有了一个初步的印象。canal的代码模块、流程等比较清晰,可以比较方便地在其上进行定制开发。