Zeppelin源码分析-notebook持久化
Notebook的持久化系统主要的类图如下: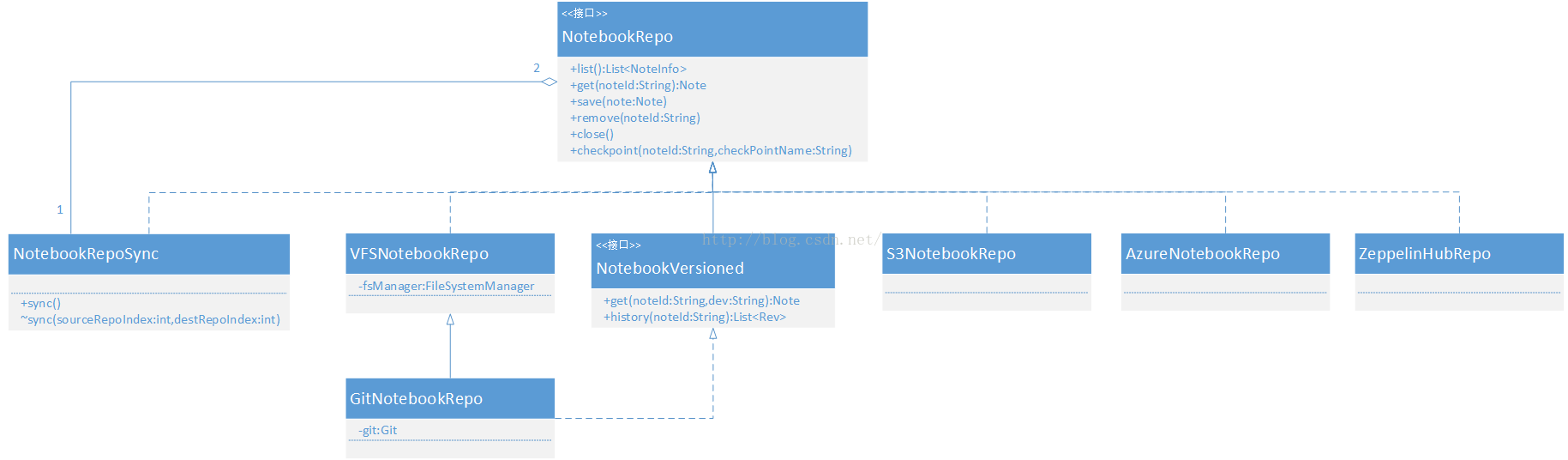
各类主要的职责如下:
- NotebookRepo是顶层接口,规定了持久化层基本的CRUD接口。
- NotebookVersioned定义了Note的版本管理接口,目前其实现类只有GitNotebookRepo(该功能目前实现的不完善,既没有实现按照rev log进行过滤检索,界面上目前也没有检索或者是回退到具体某个版本的入口),采用JGit实现。
- VFSNotebookRepo是zeppelin的默认实现类,使用apache common-vfs来实现多文件系统支持。(受配置参数zeppelin.notebook.storage控制,参见:ZeppelinConfiguration。
1 | ZEPPELIN_NOTEBOOK_STORAGE("zeppelin.notebook.storage", VFSNotebookRepo.class.getName()), |
目前common-vfs支持的文件系统虽然很多,但是由于Notebook持久化时需要RW、Create/Delete权限,实际上可用的只有如下:
| File System | Directory Contents | Authentication | Read | Write | Create/Delete | Random | Version | Rename |
|---|---|---|---|---|---|---|---|---|
| File | No | No | Yes | Yes | Yes | Read/Write | No | Yes |
| FTP | No | Yes | Yes | Yes | Yes | Read | No | Yes |
| FTPS | No | Yes | Yes | Yes | Yes | - | - | - |
| RAM | No | No | Yes | Yes | Yes | Read/Write | No | Yes |
| RES | No | No | Yes | Yes | Yes | Read/Write | No | Yes |
| SFTP | No | Yes | Yes | Yes | Yes | Read | No | Yes |
| Temp | No | No | Yes | Yes | Yes | Read/Write | No | Yes |
| WebDAV | Yes | Yes | Yes | Yes | Yes | Read/Write | Yes | Yes |
需要注意的是:不支持HDFS,由于vfs对hdfs://不支持Write、Create/Delete
NotebookRepoSync的初衷是为了让2个NotebookRepo之间进行自动同步修改,实现:在本地repo保存修改的同时,让zeppelin自动将修改同步到远程的repo上。
要启用2个repo之间的同步,需要:
a. 在zeppelin-site.xml中修改配置参数zeppelin.notebook.storage,以逗号分隔2个实现类的完整类名
b. 注意顺序,一般是将VFSNotebookRepo作为一个,而S3NotebookRepo或者是AzureNotebookRepo等作为第二个。zeppelin目前只支持最大2个Repo(maxRepoNum=2作为编译时常量),不能通过配置修改。S3NotebookRepo和AzureNotebookRepo,实现向2大云存储系统的持久化Notebook。
- ZeppelinHubRepo是为了向zeppelinhub持久化Notebook而设计的,zeppelinhub是一个类似于Github的分享网站,区别在于Github是分享git仓库的,zeppelinhub是分享notebook的。
Note的加载过程
- VFSNotebookRepo首先查看如下参数指定的地址:
1
ZEPPELIN_NOTEBOOK_DIR("zeppelin.notebook.dir", "notebook"),
默认是相对路径notebook,该路径会被解释成本地文件目录,相对于${ZEPPELIN_HOME}。
- 该路径下每个子目录会被认为存储了一个名为note.json的文件,目录名字被解释成note的id
- 使用Gson将该note.json文件反序列化成Note实例。
- 重建Note和相关对象的transient状态,参见Notebook.loadNoteFromRepo(Stringid)方法,如下:
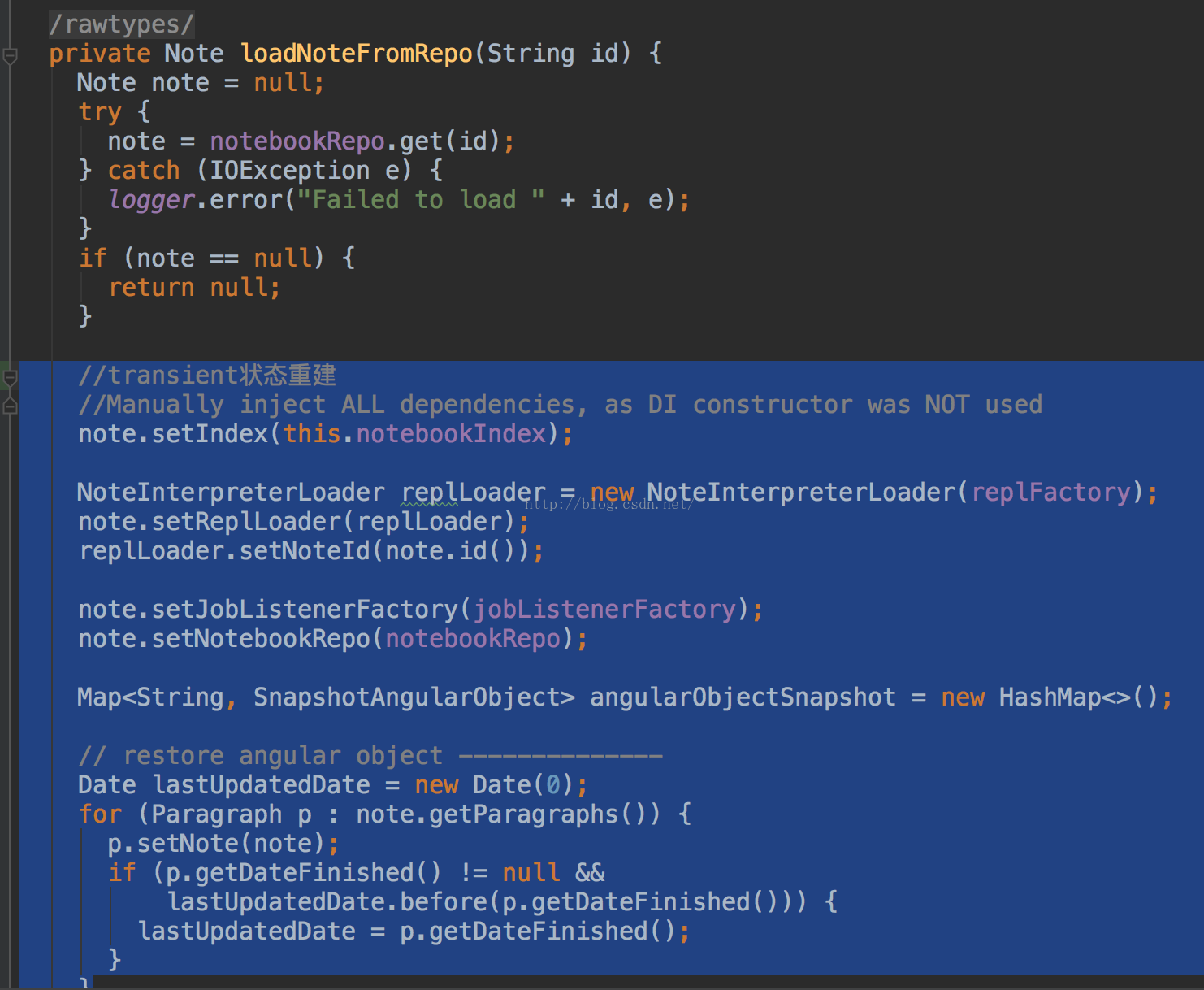
如下是zeppelin自带的notebook中的demo note。经过VFSNotebookRepo加载之后,会产生2个Note实例,id分别为2A94M5J1Z和r。1
2
3
4
5notebook/
├── 2A94M5J1Z
│ └── note.json
└── r
└── note.json
note.json中究竟序列化了什么内容?
打开id=2A94M5J1Z的note,可以看到其序列化成json后的内容
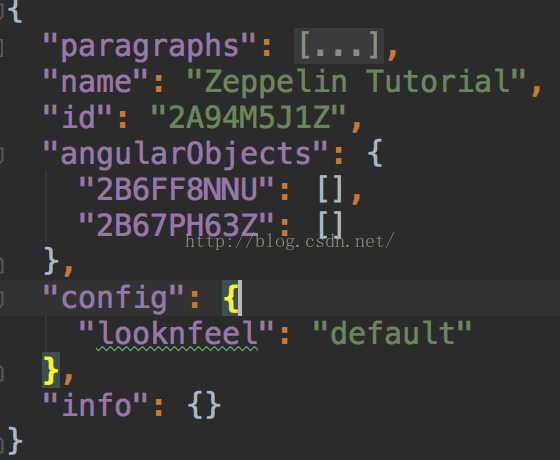
通过对比Note的字段可以发现,以上json实际是与Note的“非transient”字段一一对应的。这里会存在一个问题——为什么Note将replLoader、jobListenerFactory、repo、index和delayedPersist设置为transient?是因为这些字段(状态)可以通过Note剩下的字段以及与该Note实例相关的其他class实例的状态重建。

另外,由于在Note实例序列化成json的时候,实际是完成“图的序列化”——即Note实例“可达”的嵌套子对象(无论深度),需要一并序列化。实际上会将Paragraph、Job、GUI config、paragraphconfig(Map
以下是id=2A94M5J1Z的note的scala代码段Paragraph序列化成json之后的样子:
1 | { |
各字段都来自于Note和以上嵌套的对象。