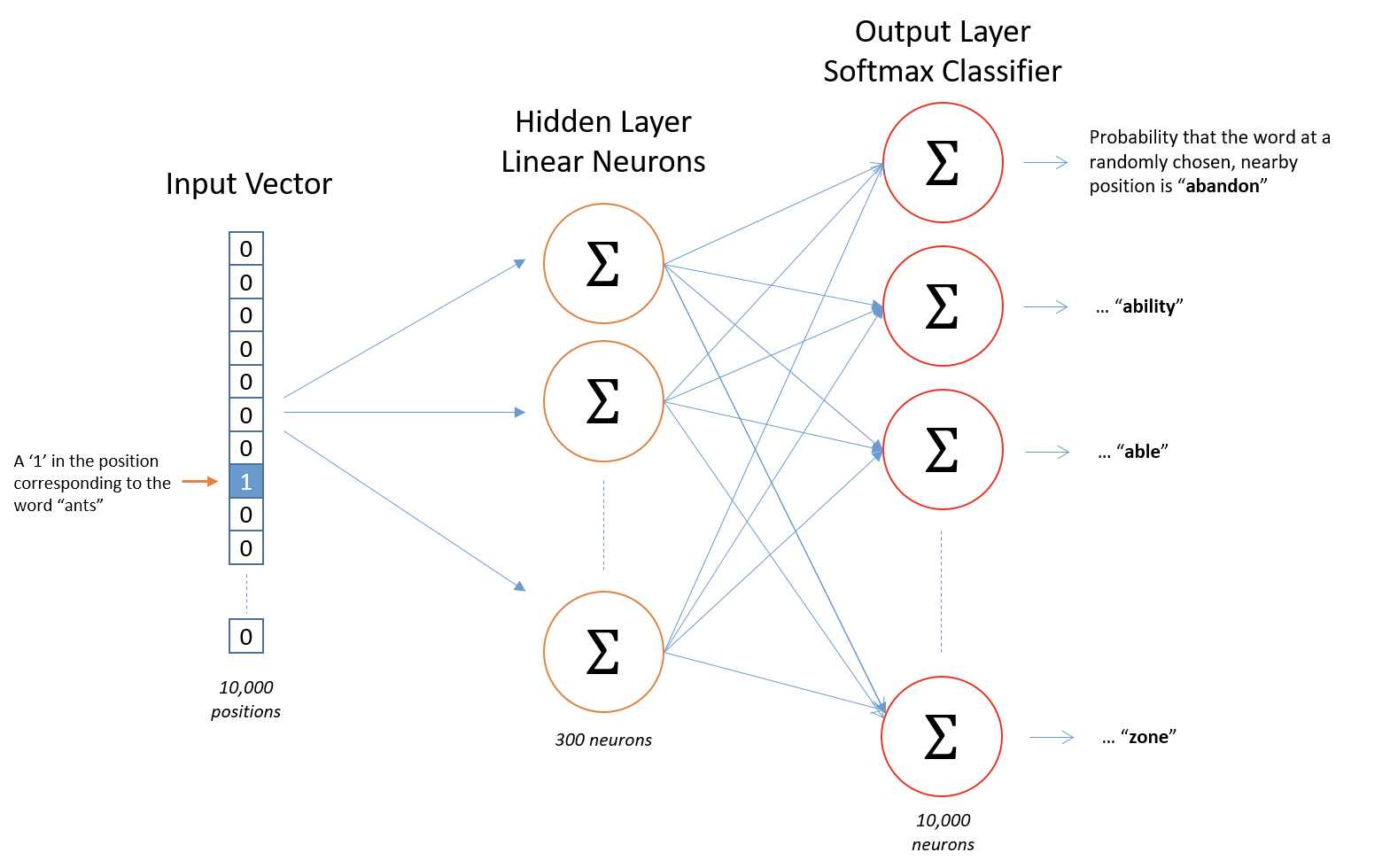
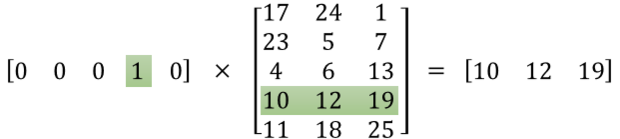
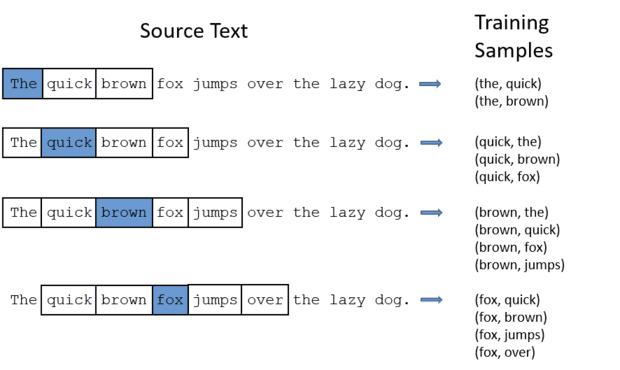
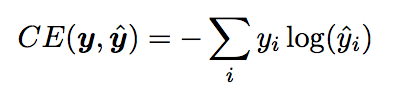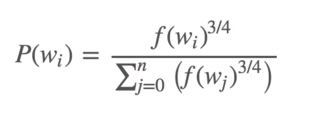# These are all the modules we'll be using later. Make sure you can import them # before proceeding further. %matplotlib inline from __future__ import print_function import collections import math import numpy as np import os import random import tensorflow as tf import zipfile from matplotlib import pylab from six.moves import range from six.moves.urllib.request import urlretrieve from sklearn.manifold import TSNE
Download the data from the source website if necessary.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
url = 'http://mattmahoney.net/dc/'
defmaybe_download(filename, expected_bytes): """Download a file if not present, and make sure it's the right size.""" ifnot os.path.exists(filename): filename, _ = urlretrieve(url + filename, filename) statinfo = os.stat(filename) if statinfo.st_size == expected_bytes: print('Found and verified %s' % filename) else: print(statinfo.st_size) raise Exception( 'Failed to verify ' + filename + '. Can you get to it with a browser?') return filename
filename = maybe_download('text8.zip', 31344016)
Read the data into a string.
1 2 3 4 5 6 7 8
defread_data(filename): """Extract the first file enclosed in a zip file as a list of words""" with zipfile.ZipFile(filename) as f: data = tf.compat.as_str(f.read(f.namelist()[0])).split() return data
words = read_data(filename) print('Data size %d' % len(words))
Build the dictionary and replace rare words with UNK token.
defbuild_dataset(words): count = [['UNK', -1]] count.extend(collections.Counter(words).most_common(vocabulary_size - 1)) dictionary = dict() for word, _ in count: dictionary[word] = len(dictionary) data = list() unk_count = 0 for word in words: if word in dictionary: index = dictionary[word] else: index = 0# dictionary['UNK'] unk_count = unk_count + 1 data.append(index) count[0][1] = unk_count reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys())) return data, count, dictionary, reverse_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(words) print('Most common words (+UNK)', count[:5]) print('Sample data', data[:10]) del words # Hint to reduce memory.
Function to generate a training batch for the skip-gram model.
defgenerate_batch(batch_size, num_skips, skip_window): global data_index assert batch_size % num_skips == 0 assert num_skips <= 2 * skip_window batch = np.ndarray(shape=(batch_size), dtype=np.int32) labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32) span = 2 * skip_window + 1# [ skip_window target skip_window ] buffer = collections.deque(maxlen=span) for _ in range(span): buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) for i in range(batch_size // num_skips): target = skip_window # target label at the center of the buffer targets_to_avoid = [ skip_window ] for j in range(num_skips): while target in targets_to_avoid: target = random.randint(0, span - 1) targets_to_avoid.append(target) batch[i * num_skips + j] = buffer[skip_window] labels[i * num_skips + j, 0] = buffer[target] buffer.append(data[data_index]) data_index = (data_index + 1) % len(data) return batch, labels
print('data:', [reverse_dictionary[di] for di in data[:8]])
for num_skips, skip_window in [(2, 1), (4, 2)]: data_index = 0 batch, labels = generate_batch(batch_size=8, num_skips=num_skips, skip_window=skip_window) print('\nwith num_skips = %d and skip_window = %d:' % (num_skips, skip_window)) print(' batch:', [reverse_dictionary[bi] for bi in batch]) print(' labels:', [reverse_dictionary[li] for li in labels.reshape(8)])
batch_size = 128 embedding_size = 128# Dimension of the embedding vector. skip_window = 1# How many words to consider left and right. num_skips = 2# How many times to reuse an input to generate a label. # We pick a random validation set to sample nearest neighbors. here we limit the # validation samples to the words that have a low numeric ID, which by # construction are also the most frequent. valid_size = 16# Random set of words to evaluate similarity on. valid_window = 100# Only pick dev samples in the head of the distribution. valid_examples = np.array(random.sample(range(valid_window), valid_size))
#######important######### num_sampled = 64# Number of negative examples to sample.
# Model. # Look up embeddings for inputs. embed = tf.nn.embedding_lookup(embeddings, train_dataset) # Compute the softmax loss, using a sample of the negative labels each time. loss = tf.reduce_mean( tf.nn.sampled_softmax_loss(weights=softmax_weights, biases=softmax_biases, inputs=embed, labels=train_labels, num_sampled=num_sampled, num_classes=vocabulary_size))
# Optimizer. # Note: The optimizer will optimize the softmax_weights AND the embeddings. # This is because the embeddings are defined as a variable quantity and the # optimizer's `minimize` method will by default modify all variable quantities # that contribute to the tensor it is passed. # See docs on `tf.train.Optimizer.minimize()` for more details. optimizer = tf.train.AdagradOptimizer(1.0).minimize(loss)
# Compute the similarity between minibatch examples and all embeddings. # We use the cosine distance: norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)) normalized_embeddings = embeddings / norm valid_embeddings = tf.nn.embedding_lookup( normalized_embeddings, valid_dataset) similarity = tf.matmul(valid_embeddings, tf.transpose(normalized_embeddings))
with tf.Session(graph=graph) as session: tf.global_variables_initializer().run() print('Initialized') average_loss = 0 for step in range(num_steps): batch_data, batch_labels = generate_batch( batch_size, num_skips, skip_window) feed_dict = {train_dataset : batch_data, train_labels : batch_labels} _, l = session.run([optimizer, loss], feed_dict=feed_dict) average_loss += l if step % 2000 == 0: if step > 0: average_loss = average_loss / 2000 # The average loss is an estimate of the loss over the last 2000 batches. print('Average loss at step %d: %f' % (step, average_loss)) average_loss = 0 # note that this is expensive (~20% slowdown if computed every 500 steps) if step % 10000 == 0: sim = similarity.eval() for i in range(valid_size): valid_word = reverse_dictionary[valid_examples[i]] top_k = 8# number of nearest neighbors nearest = (-sim[i, :]).argsort()[1:top_k+1] log = 'Nearest to %s:' % valid_word for k in range(top_k): close_word = reverse_dictionary[nearest[k]] log = '%s %s,' % (log, close_word) print(log) final_embeddings = normalized_embeddings.eval()
# actual batch_size = batch_size // (2 * skip_window) batch_size = 128 embedding_size = 128# Dimension of the embedding vector. skip_window = 1# How many words to consider left and right. num_skips = 2# How many times to reuse an input to generate a label. # We pick a random validation set to sample nearest neighbors. here we limit the # validation samples to the words that have a low numeric ID, which by # construction are also the most frequent. valid_size = 16# Random set of words to evaluate similarity on. valid_window = 100# Only pick dev samples in the head of the distribution. valid_examples = np.array(random.sample(range(valid_window), valid_size))
#######important######### num_sampled = 64# Number of negative examples to sample.
# Compute the softmax loss, using a sample of the negative labels each time. loss = tf.reduce_mean( tf.nn.sampled_softmax_loss(weights=softmax_weights, biases=softmax_biases, inputs=embed, labels=train_labels, num_sampled=num_sampled, num_classes=vocabulary_size))
# Optimizer. # Note: The optimizer will optimize the softmax_weights AND the embeddings. # This is because the embeddings are defined as a variable quantity and the # optimizer's `minimize` method will by default modify all variable quantities # that contribute to the tensor it is passed. # See docs on `tf.train.Optimizer.minimize()` for more details. optimizer = tf.train.AdagradOptimizer(1.0).minimize(loss)
# Compute the similarity between minibatch examples and all embeddings. # We use the cosine distance: norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)) normalized_embeddings = embeddings / norm valid_embeddings = tf.nn.embedding_lookup( normalized_embeddings, valid_dataset) similarity = tf.matmul(valid_embeddings, tf.transpose(normalized_embeddings))
with tf.Session(graph=graph) as session: tf.global_variables_initializer().run() print('Initialized') average_loss = 0 for step in range(num_steps): batch_data, batch_labels = get_cbow_batch( batch_size, num_skips, skip_window) feed_dict = {train_dataset : batch_data, train_labels : batch_labels} _, l = session.run([optimizer, loss], feed_dict=feed_dict) average_loss += l if step % 2000 == 0: if step > 0: average_loss = average_loss / 2000 # The average loss is an estimate of the loss over the last 2000 batches. print('Average loss at step %d: %f' % (step, average_loss)) average_loss = 0 # note that this is expensive (~20% slowdown if computed every 500 steps) if step % 10000 == 0: sim = similarity.eval() for i in range(valid_size): valid_word = reverse_dictionary[valid_examples[i]] top_k = 8# number of nearest neighbors nearest = (-sim[i, :]).argsort()[1:top_k+1] log = 'Nearest to %s:' % valid_word for k in range(top_k): close_word = reverse_dictionary[nearest[k]] log = '%s %s,' % (log, close_word) print(log) final_embeddings = normalized_embeddings.eval()
1 2 3 4 5 6
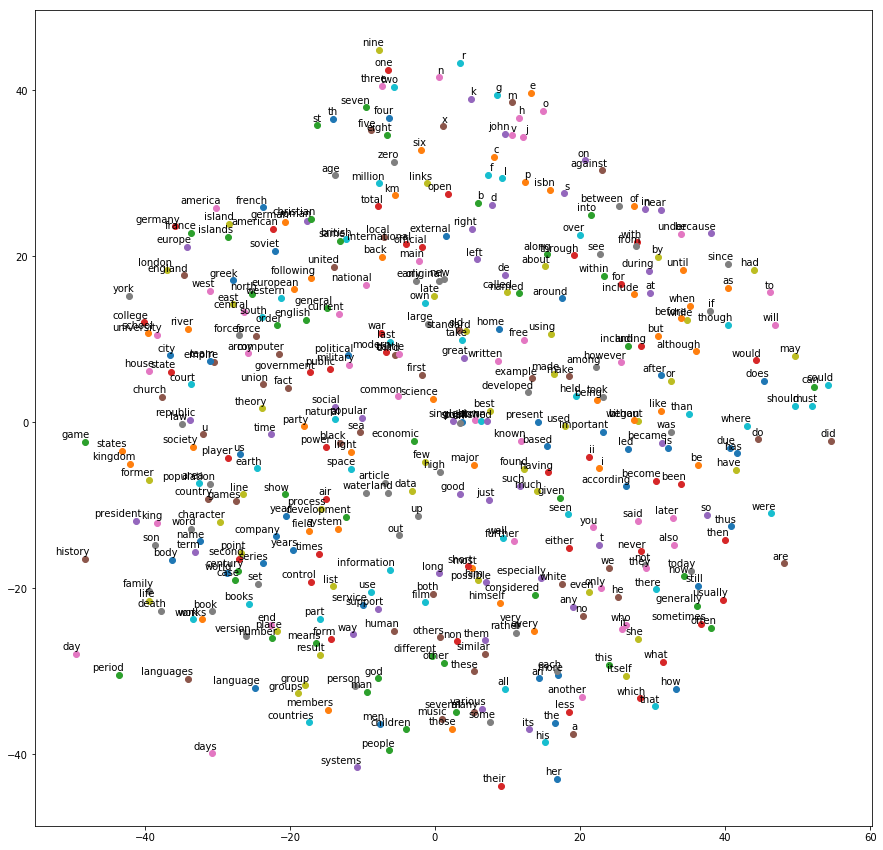
num_points = 400
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000) two_d_embeddings = tsne.fit_transform(final_embeddings[1:num_points+1, :]) words = [reverse_dictionary[i] for i in range(200, num_points+1)] plot(two_d_embeddings, words)