introduction to seaborn
Seaborn(sns)官方文档学习笔记
一直苦于没有系统学习seanborn的教程,似乎市面上也还没有完整的官方文档的学习资料。终于下决心用几天的时间通读下官方文档,并把记录下来。
基于官方0.71版本,所有代码和图片皆已验证,与官方结论不符的地方会进行标注。如果有翻译失当或理解有误的地方,敬请随意指正!
第一章 艺术化的图表控制
一个引人入胜的图表非常重要,赏心悦目的图形不但能让数据探索中一些重要的细节更容易被挖掘,也能更有利于在与观众交流分析结果的过程中吸引观众的注意力并使观众们更容易记住结论。
Matplotlib无疑是高度可定制的,但快速实施出吸引人的细节就变得有些复杂。Seaborn作为一个带着定制主题和高级界面控制的Matplotlib扩展包,能让绘图变得更轻松,本部分主要介绍seaborn是如何对matplotlib输出的外观进行控制的。
1 | %matplotlib inline |
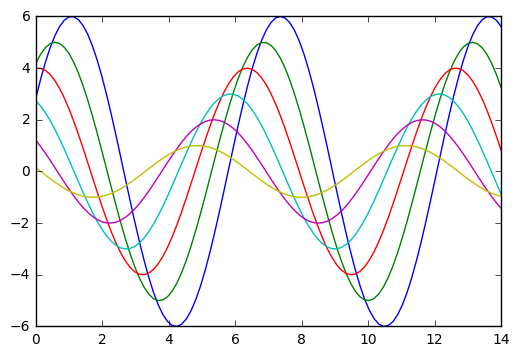
定义一个含偏移的正弦图像,来比较传统的matplotlib和seaborn的不同:
1 | def sinplot(flip=1): |
使用matplotlib默认设置的图形效果:
1 | sinplot() |
1 | import seaborn as sns |
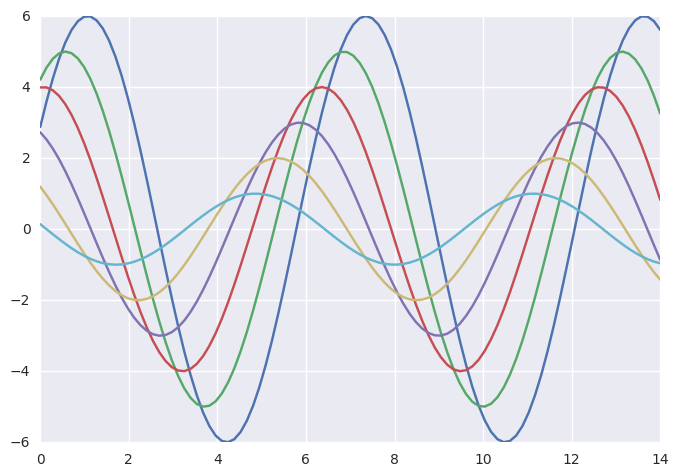
seaborn默认的灰色网格底色灵感来源于matplotlib却更加柔和。大多数情况下,图应优于表。seaborn的默认灰色网格底色避免了刺目的干扰,对于多个方面的图形尤其有用,是一些更复杂的工具的核心。
Seaborn将matplotlib参数分成两个独立的组。第一组设定了美学风格,第二组则是不同的度量元素,这样就可以很容易地添加到代码当中了。
操作这些参数的接口是两对函数。为了控制样式,使用axesstyle()和setstyle()函数。为了扩展绘图,请使用plotting_context()和set_context()函数。在这两种情况下,第一个函数返回一个参数字典,第二个函数则设置matplotlib默认属性。
样式控制:axes_style() and set_style()
有5个seaborn的主题,适用于不同的应用和人群偏好:
- darkgrid 黑色网格(默认)
- whitegrid 白色网格
- dark 黑色背景
- white 白色背景
- ticks 应该是四周都有刻度线的白背景?
网格能够帮助我们查找图表中的定量信息,而灰色网格主题中的白线能避免影响数据的表现,白色网格主题则类似的,当然更适合表达“重数据元素”(heavy data elements不理解)
1 | sns.set_style("whitegrid") |
<matplotlib.axes._subplots.AxesSubplot at 0x119eb8a58>
对于许多场景,(特别是对于像对话这样的设置,您主要想使用图形来提供数据模式的印象),网格就不那么必要了
1 | sns.set_style("dark") |
1 | sns.set_style("white") |
有时你可能想要给情节增加一点额外的结构,这就是ticks参数的用途:
1 | sns.set_style("ticks") |
特别的可以通过sns.axes_style(style=None, rc=None) 返回一个sns.set_style()可传的参数的字典
通过类似sns.set_style(“ticks”, {“xtick.major.size”: 8, “ytick.major.size”: 8})的方式写入更具体的配置样式。
关于sns.axes_style()下面会有说明和运行结果
用despine()进行边框控制
white和ticks参数的样式,都可以删除上方和右方坐标轴上不需要的边框,这在matplotlib中是无法通过参数实现的,却可以在seaborn中通过despine()函数轻松移除他们。
1 | sns.set_style("white") |
一些图的边框可以通过数据移位,当然调用despine()也能做同样的事。当边框没有覆盖整个数据轴的范围的时候,trim参数会限制留存的边框范围。
1 | sns.set_style("whitegrid") |
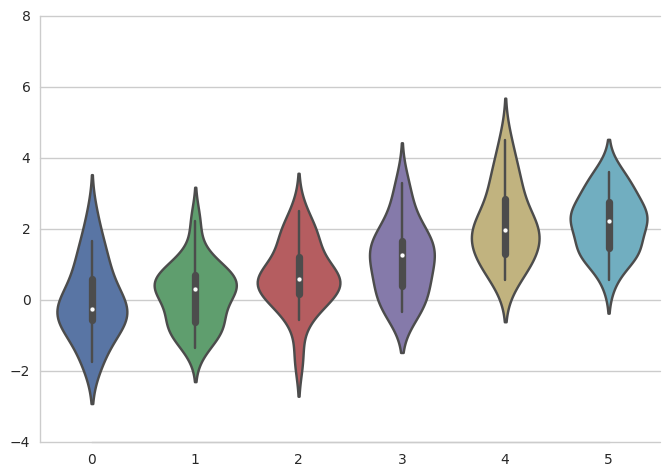
你也可以通过往despine()中添加参数去控制边框
1 | sns.set_style("whitegrid") |
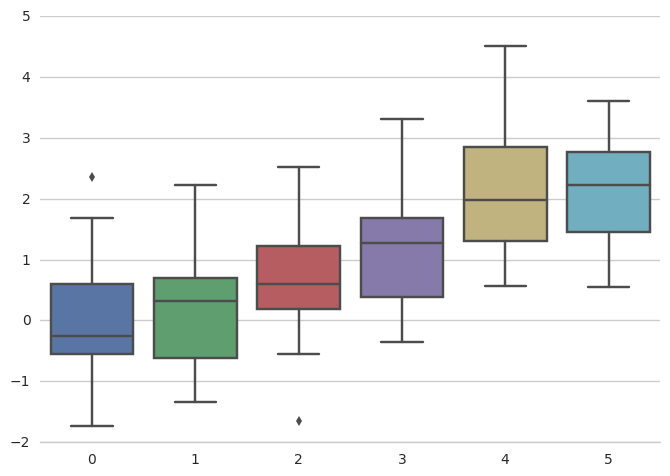
despine(fig=None, ax=None, top=True, right=True, left=False, bottom=False, offset=None, trim=False)
从plot()函数中移除顶部或右边的边框
临时设定图形样式
虽然来回切换非常容易,但sns也允许用with语句中套用axes_style()达到临时设置参数的效果(仅对with块内的绘图函数起作用)。这也允许创建不同风格的坐标轴。
1 | with sns.axes_style("darkgrid"): |
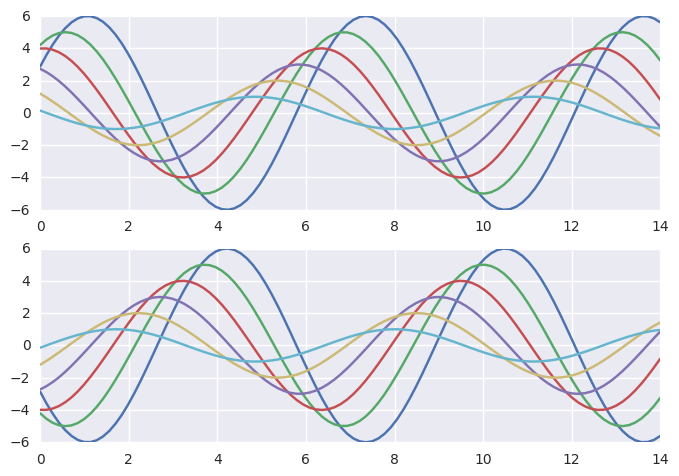
seaborn样式中最重要的元素
如果您想要定制seanborn的样式,可以将参数字典传递给axes_style()和set_style()的rc参数。注意,只能通过该方法覆盖样式定义的一部分参数。(然而,更高层次的set()函数接受任何matplotlib参数的字典)。
如果您想要查看包含哪些参数,您可以只调用该函数而不带参数,这将返回当前设置的字典:
1 | sns.axes_style() |
{'axes.axisbelow': True,
'axes.edgecolor': '.8',
'axes.facecolor': 'white',
'axes.grid': True,
'axes.labelcolor': '.15',
'axes.linewidth': 1.0,
'figure.facecolor': 'white',
'font.family': ['sans-serif'],
'font.sans-serif': ['Arial',
'Liberation Sans',
'Bitstream Vera Sans',
'sans-serif'],
'grid.color': '.8',
'grid.linestyle': '-',
'image.cmap': 'Greys',
'legend.frameon': False,
'legend.numpoints': 1,
'legend.scatterpoints': 1,
'lines.solid_capstyle': 'round',
'text.color': '.15',
'xtick.color': '.15',
'xtick.direction': 'out',
'xtick.major.size': 0.0,
'xtick.minor.size': 0.0,
'ytick.color': '.15',
'ytick.direction': 'out',
'ytick.major.size': 0.0,
'ytick.minor.size': 0.0}
或许,你可以试试不同种类的参数效果
1 | sns.set_style("darkgrid", {"axes.facecolor": ".9"}) |
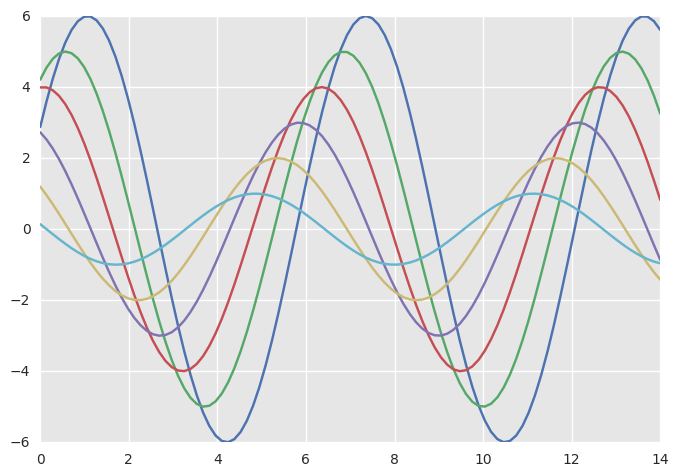
通过 plotting_context() 和 set_context() 调整绘图元素
另一组参数控制绘图元素的规模,这应该让您使用相同的代码来制作适合在较大或较小的情节适当的场景中使用的情节。
首先,可以通过sns.set()重置参数。
1 | sns.set() |
四种预设,按相对尺寸的顺序(线条越来越粗),分别是paper,notebook, talk, and poster。notebook的样式是默认的,上面的绘图都是使用默认的notebook预设。
1 | sns.set_context("paper") |
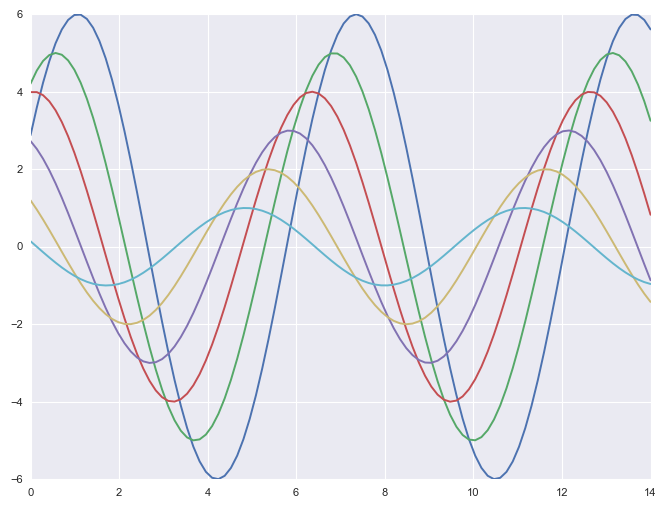
1 | # default 默认设置 |
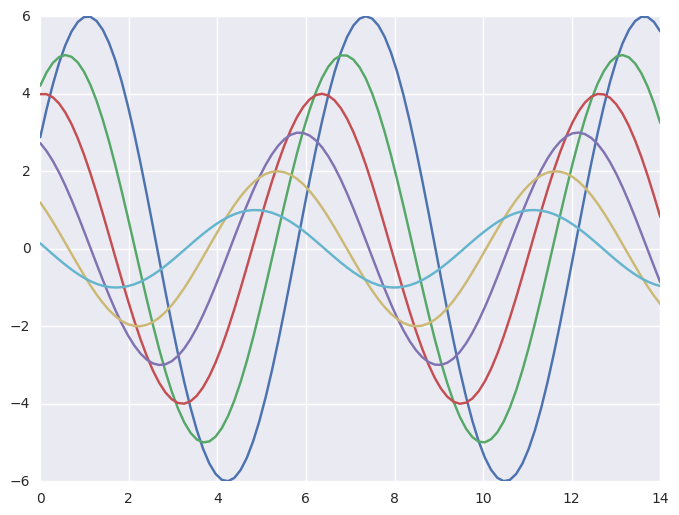
1 | sns.set_context("talk") |
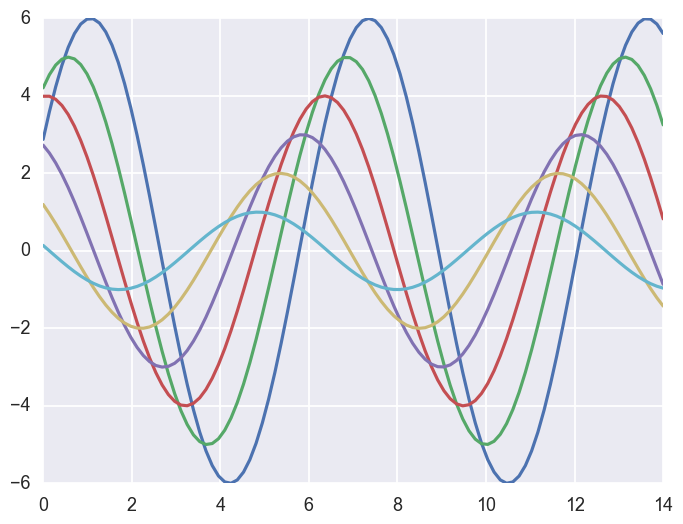
1 | sns.set_context("poster") |
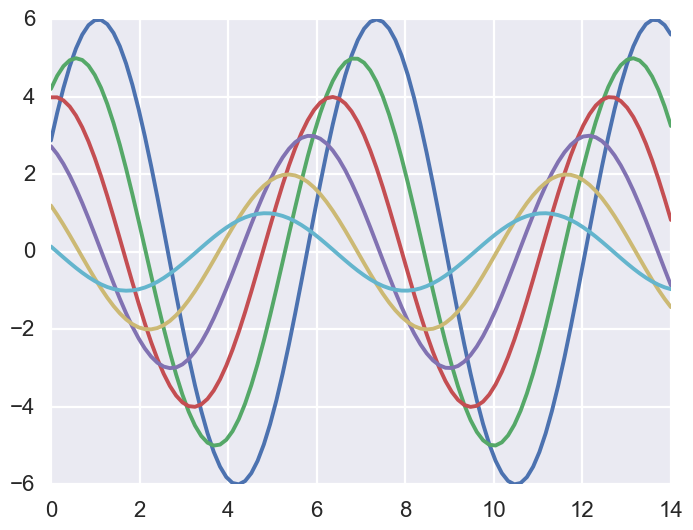
通过观察各种样式的结果,你应当可以了解context函数
类似的,还可以使用其中一个名称来调用set_context()来设置参数,您可以通过提供参数值的字典来覆盖参数。
通过更改context还可以独立地扩展字体元素的大小。(这个选项也可以通过顶级set()函数获得)。
1 | sns.set_context("notebook", font_scale=1.5, rc={"lines.linewidth": 2.5}) |
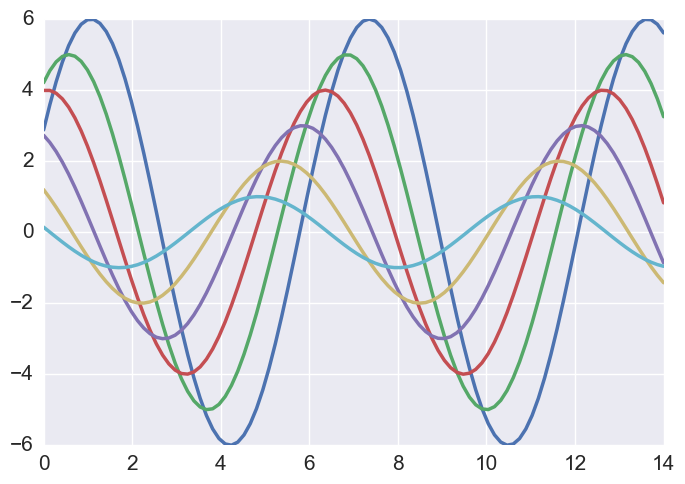
类似地(尽管它可能用处不大),也可以使用with嵌套语句进行临时的设置。
样式和上下文都可以用set()函数快速地进行配置。这个函数还设置了默认的颜色选项,在下一节将详细介绍这一功能。
第二章 斑驳陆离的调色板
颜色显然比图形风格的其他方面都更加重要,因为颜色使用得当就可以有效显示或隐藏数据中的特征。有许多的好资源都可以了解关于在可视化中使用颜色的技巧,推荐Rob Simmon的《series of blog posts》和这篇进阶的技术文章,matplotlib文档现在也有一个很好的教程,说明了如何在内置色彩映射中构建的一些感知特性。
Seaborn让你更容易选择和使用那些适合你数据和视觉的颜色。
1 | sns.set(rc={"figure.figsize": (6, 6)}) |
通过color_palette()创建调色板
最重要的直接设置调色板的函数就是color_palette()。这个函数提供了许多(并非所有)在seaborn内生成颜色的方式。并且它可以用于任何函数内部的palette参数设置(在某些情况下当需要多种颜色时也可以传入到color参数)
color_palette()允许任意的seaborn调色板或matplotlib的颜色映射(除了jet,你应该完全不使用它)。它还可以使用任何有效的matplotlib格式指定的颜色列表(RGB元组、十六进制颜色代码或HTML颜色名称)。返回值总是一个RGB元组的列表。
最后,直接调用没有传入参数的color_palette()将返回默认的颜色循环。
对应的函数set_palette()接受相同的参数,并为所有图设置默认的颜色循环。你也可以在with块中使用color_palette()来实现临时的更改调色板配置(下面有详细例子)。
通常在不知道数据的具体特征的情况下不可能知道什么类型的调色板或颜色映射对于一组数据来说是最好的。因此,我们将用三种不同类型的调色板:分类色板、连续色板和离散色板,来区分和使用color_palette()函数。
分类色板
分类色板(定性)是在区分没有固定顺序的数据时最好的选择。
在导入seaborn库后,默认的颜色循环被更改为一组六种颜色。虽然这些颜色可能会让你想起matplotlib的标准颜色循环,但他们无疑更赏心悦目一些。
1 | current_palette = sns.color_palette() |

默认颜色主题共有六种不同的变化分别是:deep, muted, pastel, bright, dark, 和 colorblind。类似下面的方式直接传入即可。
1 | current_palette = sns.color_palette("dark") |

1 | current_palette = sns.color_palette("muted") |

1 | current_palette = sns.color_palette("pastel") |
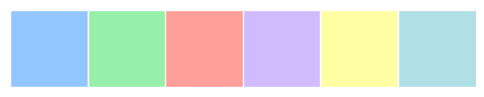
1 | current_palette = sns.color_palette("bright") |

1 | current_palette = sns.color_palette("colorblind") |

使用圆形颜色系统
当你有六个以上的分类要区分时,最简单的方法就是在一个圆形的颜色空间中画出均匀间隔的颜色(这样的色调会保持亮度和饱和度不变)。这是大多数的当他们需要使用比当前默认颜色循环中设置的颜色更多时的默认方案。
最常用的方法是使用hls的颜色空间,这是RGB值的一个简单转换。
1 | sns.palplot(sns.color_palette("hls", 8)) |

当然,也可以使用hls_palette()函数来控制颜色的亮度和饱和。
1 | sns.palplot(sns.hls_palette(8, l=.3, s=.8)) |

由于人类视觉系统的工作方式,会导致在RGB度量上强度一致的颜色在视觉中并不平衡。比如,我们黄色和绿色是相对较亮的颜色,而蓝色则相对较暗,使得这可能会成为与hls系统一致的一个问题。
为了解决这一问题,seaborn为husl系统提供了一个接口,这也使得选择均匀间隔的色彩变得更加容易,同时保持亮度和饱和度更加一致。
1 | sns.palplot(sns.color_palette("husl", 8)) |

使用分类颜色调色板
另一种视觉上令人愉悦的分类调色板来自于Color Brewer工具(它也有连续调色板和离散调色板,我们将在下面的图中看到)。这些也存在于matplotlib颜色映射中,但是它们没有得到适当的处理。在这里,当你要求一个定性颜色的调色板时,你总是会得到离散的颜色,但这意味着在某一点它们会开始循环。
Color Brewer工具的一个很好的特点是,它提供了一些关于调色板是色盲安全的指导。有各种各样的适合色盲的颜色,但是最常见的变异导致很难区分红色和绿色。一般来说,避免使用红色和绿色来表示颜色以区分元素是一个不错的主意。
1 | sns.palplot(sns.color_palette("Paired")) |

1 | sns.palplot(sns.color_palette("Set2", 10)) |

为了帮助您从Color Brewer工具中选择调色板,这里有choose_colorbrewer_palette()函数。这个函数必须在IPython notebook中使用,它将启动一个交互式小部件,让您浏览各种选项并调整参数。
当然,您可能只想使用一组您特别喜欢的颜色。因为color_palette()接受一个颜色列表,这很容易做到。
1 | flatui = ["#9b59b6", "#3498db", "#95a5a6", "#e74c3c", "#34495e", "#2ecc71"] |

1 | sns.choose_colorbrewer_palette("sequential") |

1 | sns.choose_colorbrewer_palette("sequential",as_cmap=True) |

使用xkcd颜色来命名颜色
xkcd包含了一套众包努力的针对随机RGB色的命名。产生了954个可以随时通过xdcd_rgb字典中调用的命名颜色。
1 | plt.plot([0, 1], [0, 1], sns.xkcd_rgb["pale red"], lw=3) |
如果你想花一些时间挑选颜色,或许这种交互式的可视化(官方链接失效)是非常有帮助的。除了将单一颜色从xkcd_rgb字典中取出,也可以通过名称列表传入xkcd_palette()函数中取得颜色组。
1 | colors = ["windows blue", "amber", "greyish", "faded green", "dusty purple"] |

连续色板
调色板中第二大类称为“顺序”。这种颜色映射对应的是从相对低价值(无意义)数据到高价值(有意义)的数据范围。虽然有时候你会需要一个连续的离散颜色调色板,用他们像kdeplot()或者corrplot()功能映射更加常见(以及可能类似的matplotlib功能)。
非常可能的是见到jet色彩映射(或其他采用调色板)在这种情况下使用,因为色彩范围提供有关数据的附加信息。然而,打的色调变化中往往会引入不连续性中不存在的数据和视觉系统不能自然的通过“彩虹色”定量产生“高”、“低”之分。其结果是,这样的可视化更像是一个谜题,模糊了数据中的信息而并非揭示这种信息。事实上,jet调色板可能非常糟糕,因为最亮的颜色,黄色和青色用于显示中间数值,这就导致强调了一些没有意义的数据而忽视了端点的数据。
所以对于连续的数据,最好是使用那些在色调上相对细微变化的调色板,同时在亮度和饱和度上有很大的变化。这种方法将自然地吸引数据中相对重要的部分
Color Brewer的字典中就有一组很好的调色板。它们是以在调色板中的主导颜色(或颜色)命名的。
1 | sns.palplot(sns.color_palette("Blues")) |

就像在matplotlib中一样,如果您想要翻转渐变,您可以在面板名称中添加一个_r后缀。
1 | sns.palplot(sns.color_palette("BuGn_r")) |

seaborn还增加了一个允许创建没有动态范围的”dark”面板。如果你想按顺序画线或点,这可能是有用的,因为颜色鲜艳的线可能很难区分。
类似的,这种暗处理的颜色,需要在面板名称中添加一个_d后缀
1 | sns.palplot(sns.color_palette("GnBu_d")) |

牢记,你可能想使用choose_colorbrewer_palette()函数取绘制各种不同的选项。如果你想返回一个变量当做颜色映射传入seaborn或matplotlib的函数中,可以设置as_cmap参数为True。
cubehelix_palette()函数的连续调色板
cubehelix调色板系统具有线性增加或降低亮度和色调变化顺序的调色板。这意味着在你的映射信息会在保存为黑色和白色(为印刷)时或被一个色盲的人浏览时可以得以保留。
Matplotlib拥有一个默认的内置cubehelix版本可供创建:
1 | sns.palplot(sns.color_palette("cubehelix", 8)) |

seaborn为cubehelix系统添加一个接口使得其可以在各种变化中都保持良好的亮度线性梯度。
通过seaborn的cubehelix_palette()函数返回的调色板与matplotlib默认值稍有所不同,它不会在色轮周围旋转或覆盖更广的强度范围。seaborn还改变了排序使得更重要的值显得更暗:
1 | sns.palplot(sns.cubehelix_palette(8)) |

其他cubehelix_palette()的参数主要调整色板的视觉。两个重要的选择是:start(值的范围为03)和rot,还有rot的次数(-11之间的任意值)
1 | sns.palplot(sns.cubehelix_palette(8, start=.5, rot=-.75)) |

你也可以控制断点的亮度和甚至对调结果顺序
1 | sns.palplot(sns.cubehelix_palette(8, start=2, rot=0, dark=0, light=.95, reverse=True)) |

默认情况下你只会得到一些与seaborn调色板相似的颜色的列表,但你也可以让调色板返回一个可以用as_cmap=True传入seaborn或matplotlib函数的颜色映射对象
1 | sns.set_context("notebook") |
类似的,也可以在notebook中使用choose_cubehelix_palette()函数启动一个互助程序来帮助选择更适合的调色板或颜色映射。如果想让函数返回一个类似hexbin的颜色映射而非一个列表则需要传入as_cmap=True。
使用light_palette() 和dark_palette()调用定制连续调色板
这里还有一个更简单的连续调色板的使用方式,就是调用light_palette() 和dark_palette(),这与一个单一颜色和种子产生的从亮到暗的饱和度的调色板。这些函数还伴有choose_light_palette() and choose_dark_palette()函数,这些函数启动了交互式小部件来创建这些调色板。
1 | sns.palplot(sns.light_palette("green")) |


这些调色板结果也可以颠倒
1 | sns.palplot(sns.light_palette("navy", reverse=True)) |

当然也可以创建一个颜色映射对象取代颜色列表
1 | pal = sns.dark_palette("palegreen", as_cmap=True) |
默认情况下,任何有效的matplotlib颜色可以传递给input参数。也可以在hls或husl空间中提供默认的rgb元组,您还可以使用任何有效的xkcd颜色的种子。
1 | sns.palplot(sns.light_palette((210, 90, 60), input="husl")) |


需要注意的是,为默认的input空间提供交互的组件是husl,这与函数自身默认的并不同,但这在背景下却是更有用的。
离散色板
调色板中的第三类被称为“离散”。用于可能无论大的低的值和大的高的值都非常重要的数据。数据中通常有一个定义良好的中点。例如,如果你正在绘制温度变化从基线值,最好使用不同色图显示相对降低和相对增加面积的地区。
选择离散色板的规则类似于顺序色板,除了你想满足一个强调的颜色中点以及用不同起始颜色的两个相对微妙的变化。同样重要的是,起始值的亮度和饱和度是相同的。
同样重要的是要强调,应该避免使用红色和绿色,因为大量的潜在观众将无法分辨它们。
你不应该感到惊讶的是,Color Brewer颜色字典里拥有一套精心挑选的离散颜色映射:
1 | sns.palplot(sns.color_palette("BrBG", 7)) |


另一个在matplotlib中建立的明智的选择是coolwarm面板。请注意,这个颜色映射在中间值和极端之间并没有太大的对比。
1 | sns.palplot(sns.color_palette("coolwarm", 7)) |

用diverging_palette()使用定制离散色板
你也可以使用海运功能diverging_palette()为离散的数据创建一个定制的颜色映射。(当然也有一个类似配套的互动工具:choose_diverging_palette())。该函数使用husl颜色系统的离散色板。你需随意传递两种颜色,并设定明度和饱和度的端点。函数将使用husl的端点值及由此产生的中间值进行均衡。
1 | sns.palplot(sns.diverging_palette(220, 20, n=7)) |


sep参数控制面板中间区域的两个渐变的宽度。
1 | sns.palplot(sns.diverging_palette(10, 220, sep=80, n=7)) |

也可以用中间的色调来选择调色,而不是用亮度
1 | sns.palplot(sns.diverging_palette(255, 133, l=60, n=7, center="dark")) |

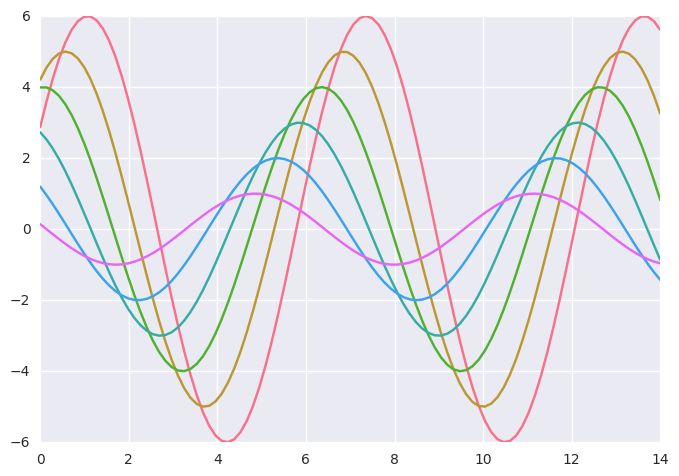
用set_palette()更改色变的默认值
color_palette() 函数有一个名为set_palette()的配套。它们之间的关系类似于在美学教程中涉及的aesthetics tutorial. set_palette()。set_palette()接受与color_palette()相同的参数,但是它会更改默认的matplotlib参数,以便成为所有的调色板配置。
1 | def sinplot(flip=1): |
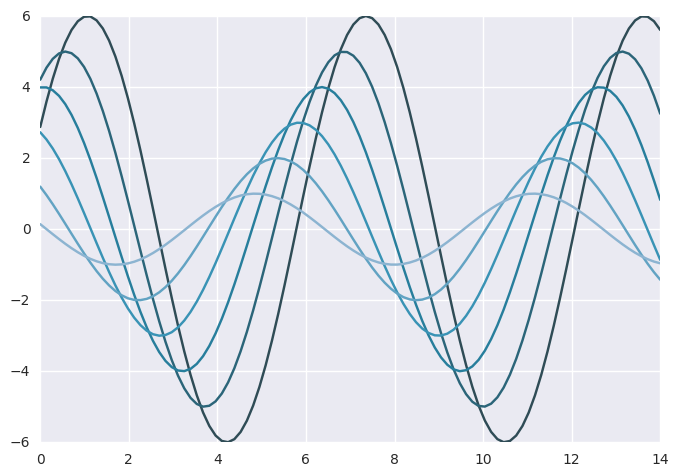
color_palette()函数也可以在一个with块中使用,以达到临时更改调色板的目的
1 | with sns.color_palette("PuBuGn_d"): |
简单常用色彩总结:
- 分类:hls husl Paired Set1~Set3(色调不同)
- 连续:Blues[蓝s,颜色+s] BuGn[蓝绿] cubehelix(同色系渐变)
- 离散:BrBG[棕绿] RdBu[红蓝] coolwarm[冷暖](双色对称)
第三章 分布数据集的可视化
在处理一组数据时,通常首先要做的是了解变量是如何分布的。这一章将简要介绍seborn中用于检查单变量和双变量分布的一些工具。你可能还想看看分类变量的章节,来看看函数的例子,这些函数让我们很容易比较变量的分布。
1 | import pandas as pd |
单变量分布
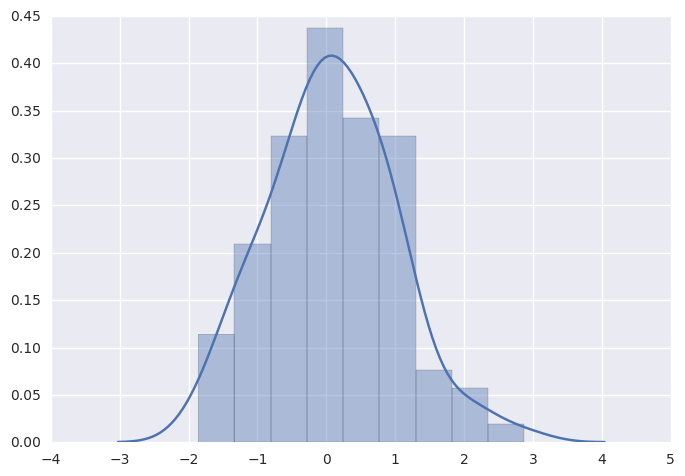
最方便的方式是快速查看单变量分布无疑是使用distplot()函数。默认情况下,这将绘制一个直方图,并拟合出核密度估计(KDE)。
1 | x = np.random.normal(size=100) |
直方图
直方图应当是非常熟悉的函数了,在matplotlib中就存在hist函数。直方图通过在数据的范围内切成数据片段,然后绘制每个数据片段中的观察次数,来表示整体数据的分布。
为了说明这一点,我们删除密度曲线并添加了地毯图,每个观察点绘制一个小的垂直刻度。您可以使用rugplot()函数来制作地毯图,但它也可以在distplot()中使用:
1 | sns.distplot(x, kde=False, rug=True); |
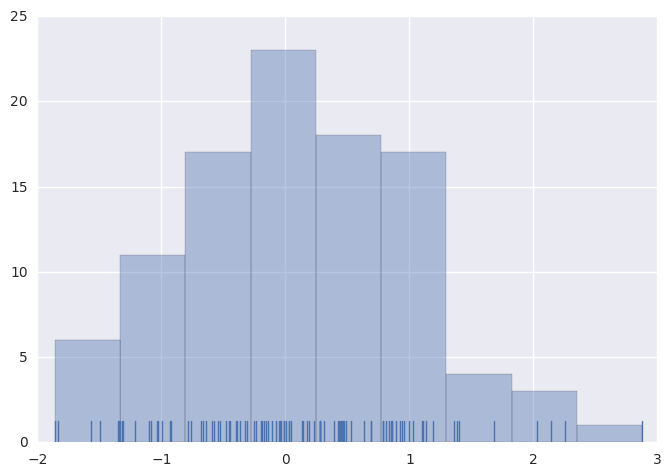
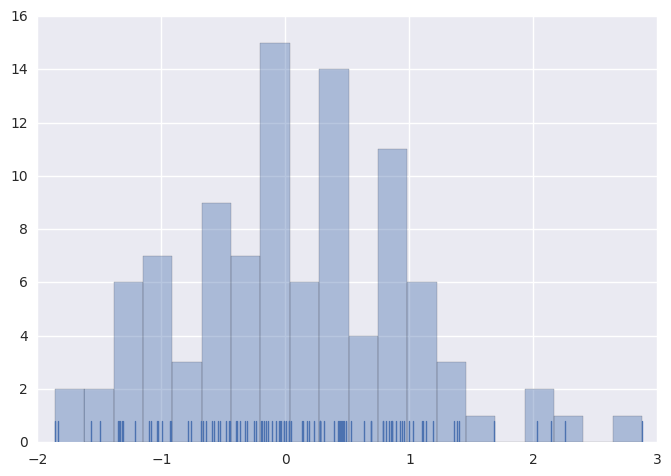
绘制直方图时,主要的选择是使用切分数据片段的数量或在何位置切分数据片段。 distplot()使用一个简单的规则来很好地猜测并给予默认的切分数量,但尝试更多或更少的数据片段可能会显示出数据中的其他特征:
1 | sns.distplot(x, bins=20, kde=False, rug=True); |
核密度估计(KDE) Kernel density estimaton
或许你对核密度估计可能不像直方图那么熟悉,但它是绘制分布形状的有力工具。如同直方图一样,KDE图会对一个轴上的另一轴的高度的观测密度进行描述:
1 | sns.distplot(x, hist=False, rug=True); |
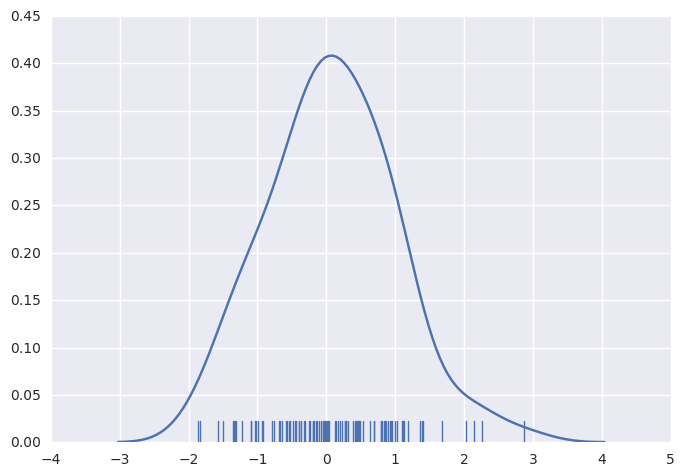
绘制KDE比绘制直方图更有计算性。所发生的是,每一个观察都被一个以这个值为中心的正态( 高斯)曲线所取代。
1 | x = np.random.normal(0, 1, size=30) |
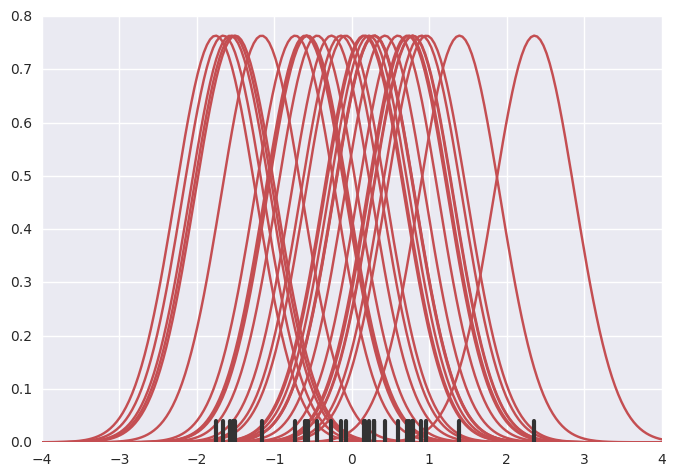
接下来,这些曲线可以用来计算支持网格中每个点的密度值。得到的曲线再用归一化使得它下面的面积等于1:
1 | density = np.sum(kernels, axis=0) |
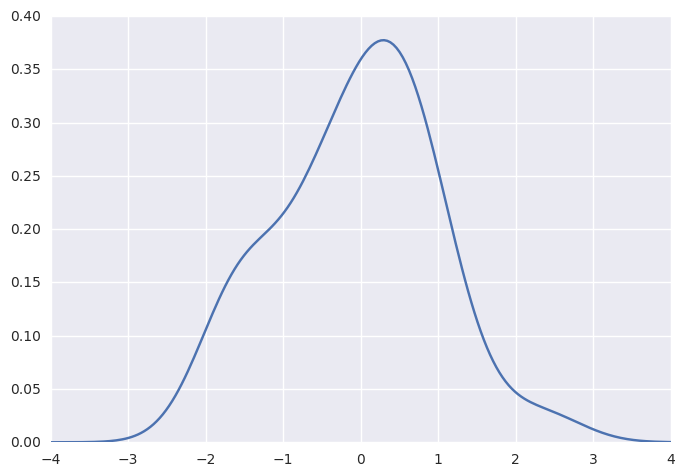
我们可以看到,如果我们在seaborn中使用kdeplot()函数,我们得到相同的曲线。 这个函数由distplot()使用,但是当您只想要密度估计时,它提供了一个更直接的界面,更容易访问其他选项:
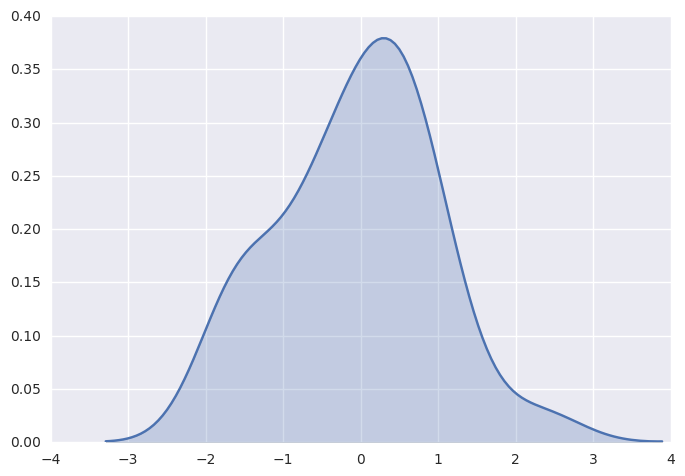
1 | sns.kdeplot(x, shade=True); |
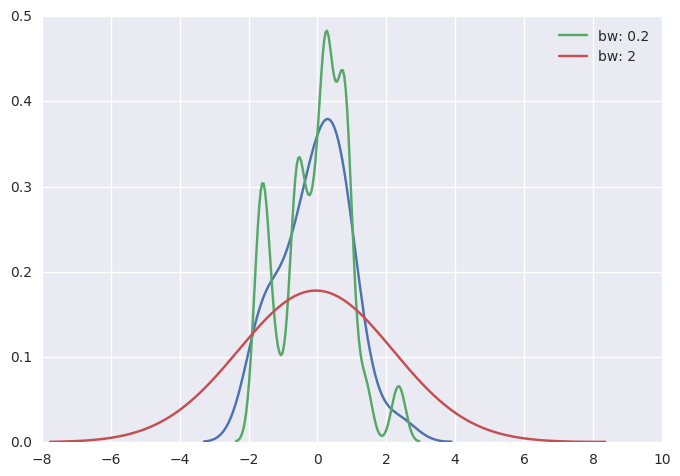
KDE的带宽bandwidth(bw)参数控制估计对数据的拟合程度,与直方图中的bin(数据切分数量参数)大小非常相似。 它对应于我们上面绘制的内核的宽度。 默认中会尝试使用通用引用规则猜测一个适合的值,但尝试更大或更小的值可能会有所帮助:
1 | sns.kdeplot(x) |
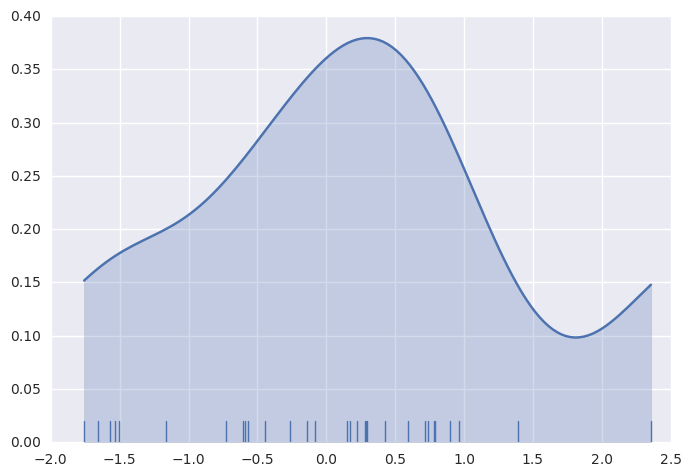
如上所述,高斯KDE过程的性质意味着估计延续了数据集中最大和最小的值。 可以通过cut参数来控制绘制曲线的极值值的距离; 然而,这只影响曲线的绘制方式,而不是曲线如何拟合:
1 | sns.kdeplot(x, shade=True, cut=0) |
拟合参数分布
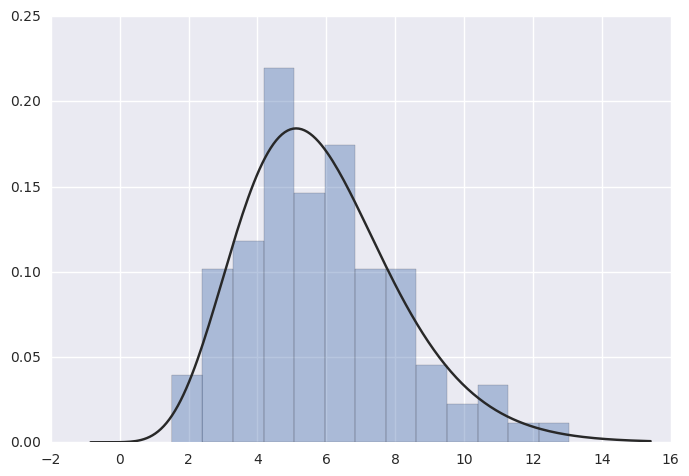
还可以使用distplot()将参数分布拟合到数据集,并可视化地评估其与观察数据的对应关系:
1 | x = np.random.gamma(6, size=200) |
绘制双变量分布
在绘制两个变量的双变量分布也是有用的。在seaborn中这样做的最简单的方法就是在jointplot()函数中创建一个多面板数字,显示两个变量之间的双变量(或联合)关系以及每个变量的单变量(或边际)分布和轴。
1 | mean, cov = [0, 1], [(1, .5), (.5, 1)] |
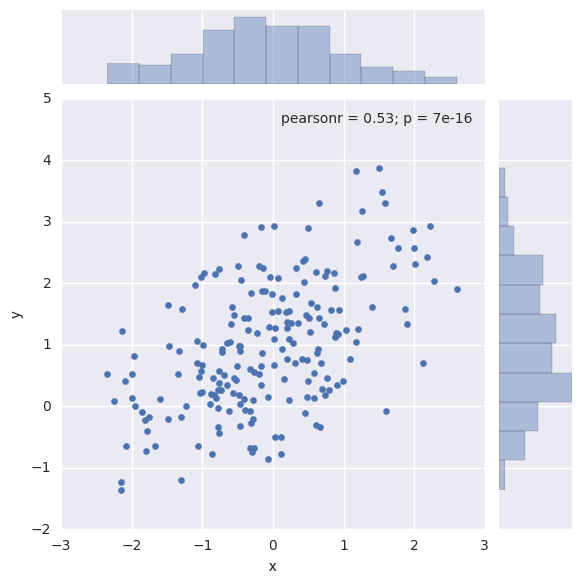
散点图
双变量分布的最熟悉的可视化方式无疑是散点图,其中每个观察结果以x和y值表示。这是两个方面的地毯图。可以使用matplotlib中的plt.scatter函数绘制散点图,它也是jointplot()函数显示的默认方式。
1 | sns.jointplot(x="x", y="y", data=df); |
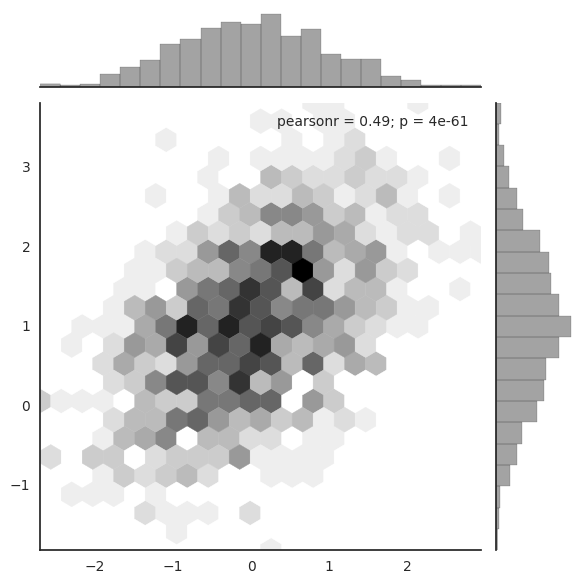
HexBin图
直方图的双变量类似物被称为“hexbin”图,因为它显示了落在六边形仓内的观测数。该图适用于较大的数据集。通过matplotlib plt.hexbin函数和jointplot()中的样式可以实现。 它最好使用白色背景:
1 | x, y = np.random.multivariate_normal(mean, cov, 1000).T |
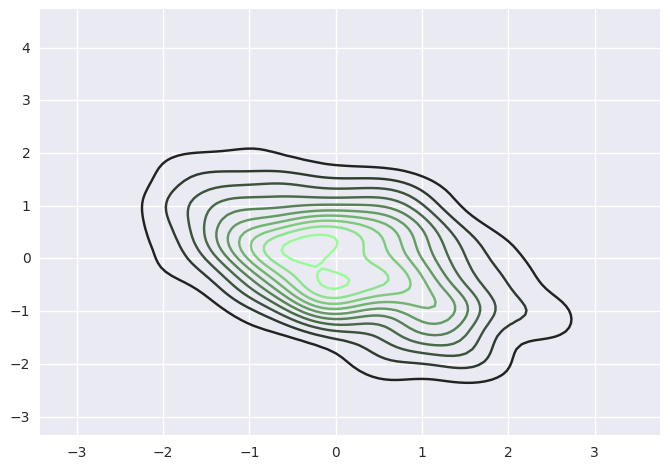
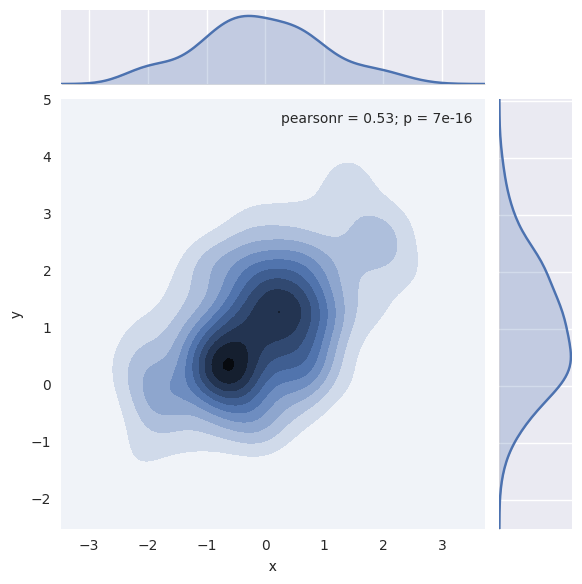
核密度估计
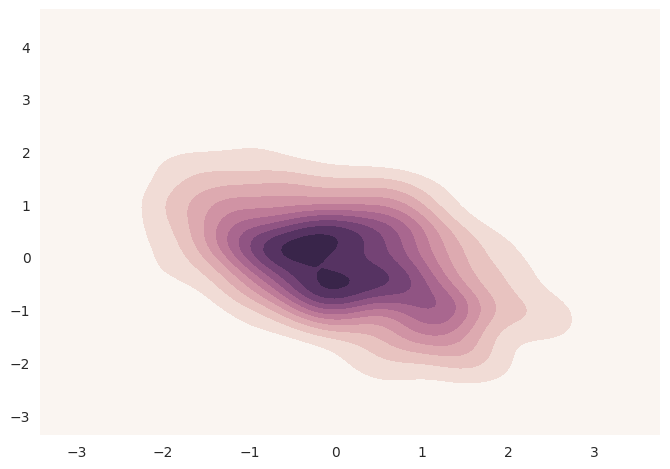
使用上述内核密度估计程序可视化双变量分布也是可行的。在seaborn中,这种图用等高线图显示,可以在jointplot()中作为样式传入参数使用:
1 | sns.jointplot(x="x", y="y", data=df, kind="kde"); |
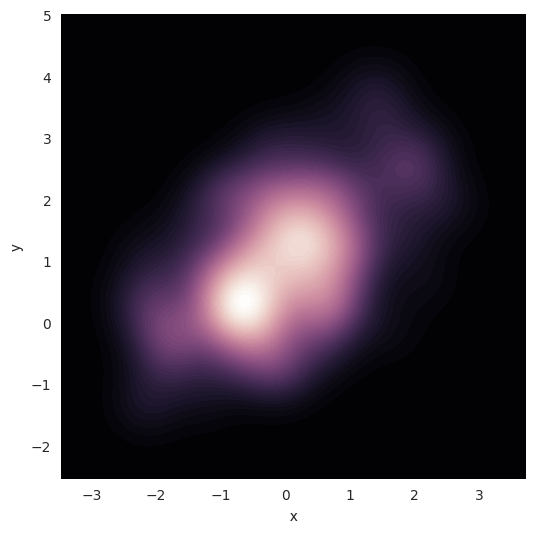
还可以使用kdeplot()函数绘制二维核密度图。这样可以将这种绘图绘制到一个特定的(可能已经存在的)matplotlib轴上,而jointplot()函数只能管理自己:
1 | f, ax = plt.subplots(figsize=(6, 6)) |
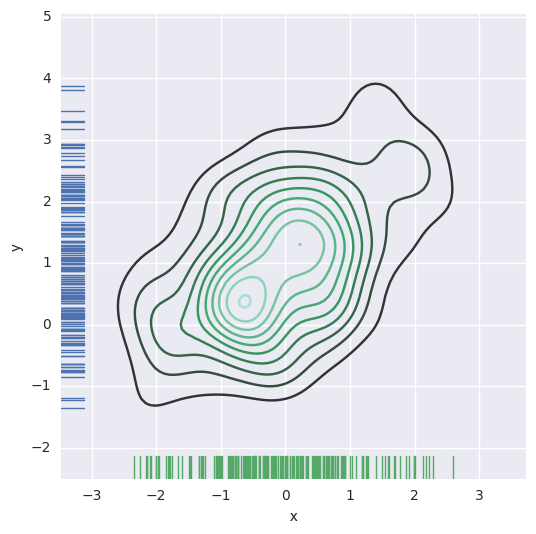
如果是希望更连续地显示双变量密度,您可以简单地增加n_levels参数增加轮廓级数:
1 | f, ax = plt.subplots(figsize=(6, 6)) |
jointplot()函数使用JointGrid来管理。为了获得更多的灵活性,您可能需要直接使用JointGrid绘制图形。jointplot()在绘制后返回JointGrid对象,您可以使用它来添加更多图层或调整可视化的其他方面:
1 | g = sns.jointplot(x="x", y="y", data=df, kind="kde", color="m") |
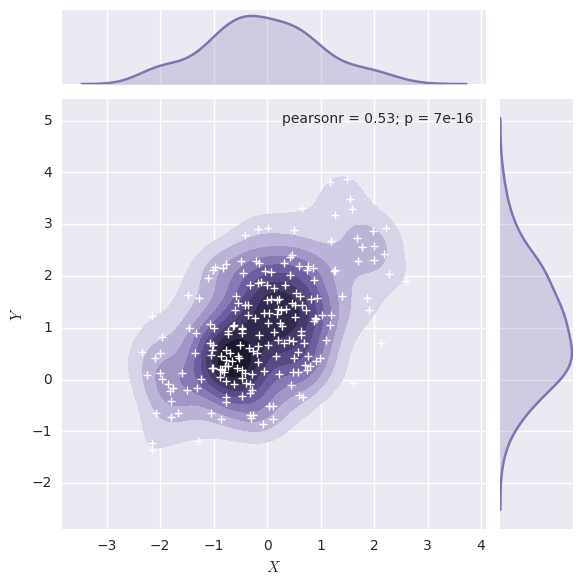
呈现数据集中成对的关系
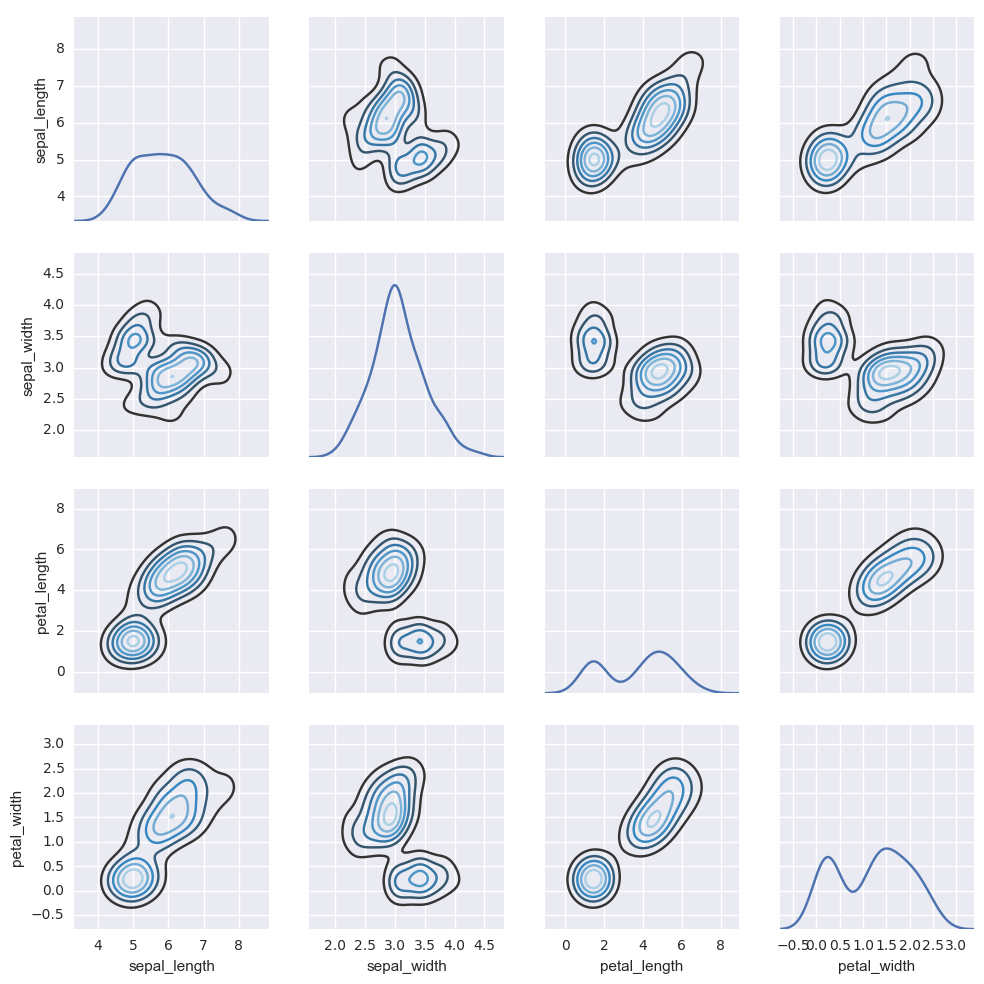
要在数据集中绘制多个成对双变量分布,可以使用pairplot()函数。这将创建一个轴的矩阵,并显示DataFrame中每对列的关系。默认情况下,它也绘制每个变量在对角轴上的单变量:
1 | iris = sns.load_dataset("iris") |
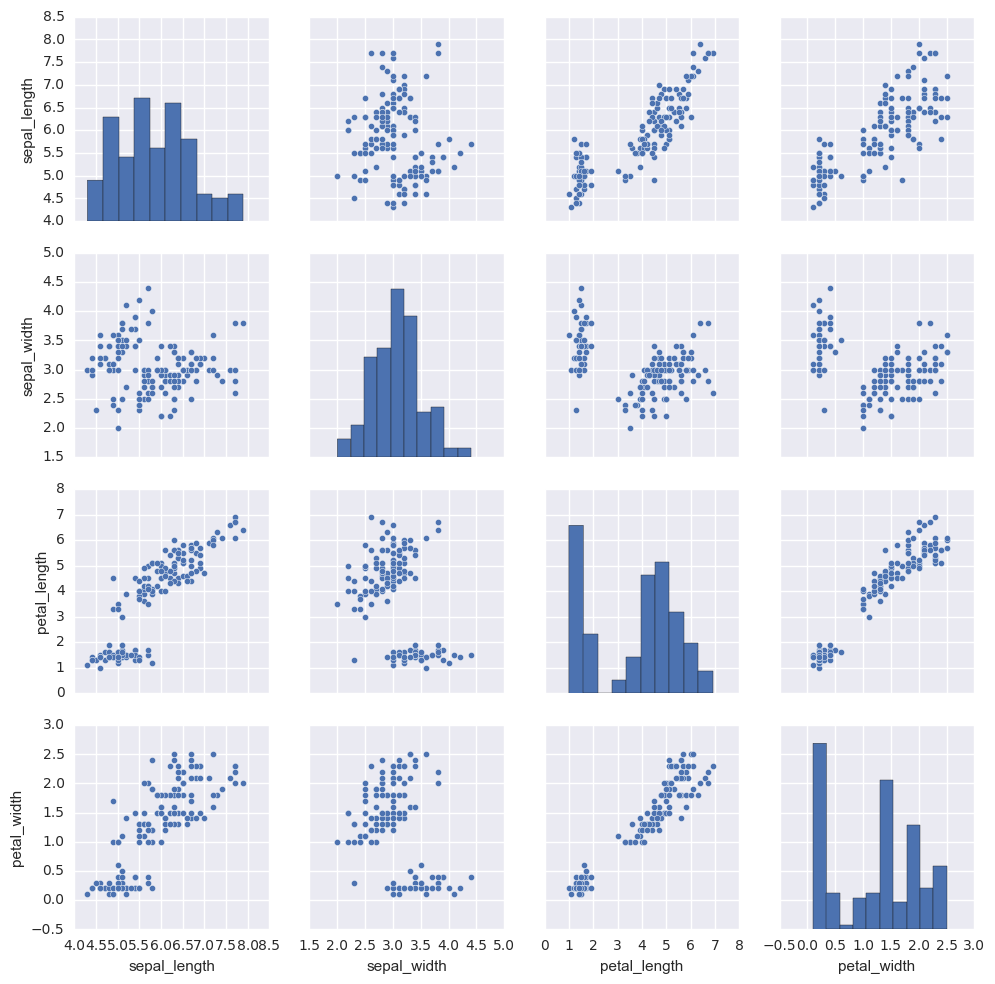
对于jointplot()和JointGrid之间的关系,pairplot()函数是建立在一个PairGrid对象上的,可以直接使用它来获得更大的灵活性:
1 | g = sns.PairGrid(iris) |