introduction_to_neo4j
文章目录
简介
“Neo4j是一个高性能的,非关系的,具有完全事务特性的,鲁棒的图数据库。” neo4j在处理复杂的网络数据时候,具有很好的性能表现[1],适用于社交网络,动态网络等场景。它基于java语言实现,有两个分发版本,社区版(community version)以GPLv3的许可在Github上开源,源码地址:https://github.com/neo4j/community;企业版,同时遵循AGPLv3和商业许可,它在社区版基础上增加了包括高可用性(High Availability),全天侯支持等特性。Neo4j的开发非常活跃,围绕它有非常多的项目,包括 REST API 绑定(各种语言实现列表),空间数据库支持(源码地址)等。
安装
Git 安装
Git的安装非常简单,大多数的Linux发行版本的源中都打包好。以Ubuntu 为例(仅测试Oneiric,Precise),只需要输入如下命令即可安装。
1 | sudo apt-get install git |
Maven 安装
同样的Ubuntu(我最爱系统)下,安装Maven3非常简单,输入如下命令:
1 | sudo apt-get maven |
Neo4j 安装
安装好以上两者后,我们直接从github的源码,并用maven来安装neo4j,命令如下:
1 | mkdir neo4j |
如此,neo4j即安装成功。如果需要build不同的版本可以遵照参考文献5Readme的指示来实现。
Neo4j 基本概念
Neo4j中不存在表的概念,只有两类:节点( Node )和关联( Relation ),可以简单理解为图里面的点和边。 在数据查询中,节点一般用小括号(),关联用中括号[]。 当然也隐含路径的概念,是用节点和关联表示的,如:(a)-[r]->(b),表示一条从节点a经关联r到节点b的路径。
- 节点: 图中的对象 可带若干名-值属性 可带标签 例: (m:Movie {title:”The Matrix”})
- 关系: 连接节点(有类型、带方向) 可带若干名-值属性 例:(a)-[:ACTED_IN {roles:[“Neo”]}]->(m)
Neo4j Cypher 基本操作
cypher是neo4j官网提供的声明式查询语言,非常强大,用它可以完成任意的图谱里面的查询过滤,我们知识图谱的一期项目 基本开发完毕,后面会陆续总结学习一下neo4j相关的知识。今天接着上篇文章来看下neo4j的cpyher查询的一些基本概念和语法。
Node语法
在cypher里面通过用一对小括号()表示一个节点,它在cypher里面查询形式如下:
- () 代表匹配任意一个节点
- (node1) 代表匹配任意一个节点,并给它起了一个别名
- (:Lable) 代表查询一个类型的数据
- (person:Lable) 代表查询一个类型的数据,并给它起了一个别名
- (person:Lable {name:”小王”}) 查询某个类型下,节点属性满足某个值的数据
- (person:Lable {name:”小王”,age:23}) 节点的属性可以同时存在多个,是一个AND的关系
关系语法
关系用一对-组成,关系分有方向的进和出,如果是无方向就是进和出都查询
- -> 指向一个节点
- -[role]-> 给关系加个别名
- -[:acted_in]-> 访问某一类关系
- -[role:acted_in]-> 访问某一类关系,并加了别名
- -[role:acted_in {roles:[“neo”,”hadoop”]}]-> 访问某一类关系下的某个属性的关系的数据
模式语法
模式语法是节点和关系查询语法的结合,通过模式语法我们可以进行我们想要的任意复杂的查询
1 | (p1: Person:Actor {name:”tom”})-[role:acted_in {roles:[“neo”,”actor”]}]-(m1:Movie {title:”water”}) |
模式变量
为了增加模块化和减少重复,cypher允许把模式的结果指定在一个变量或者别名中,方便后续使用或操作
1 | path = (: Person)-[:ACTED_IN]->(:Movie) |
- path是结果集的抽象封装,有多个函数可以直接从path里面提取数据如:
- nodes(path):提取所有的节点
- rels(path): 提取所有的关系 和relationships(path)相等
- length(path): 获取路径长度
条件
cypher语句也是由多个关键词组成,像SQL的
1 | select name, count() from talbe where age=24 group by name having count() >2 order by count(*) desc |
多个关键字组成的语法,cypher也非常类似,每个关键词会执行一个特定的task来处理数据 match: 查询的主要关键词 create: 类似sql里面的insert filter,project,sort,page等都有对应的功能语句 通过组合上面的一些语句,我们可以写出非常强大复杂的语法,来查询我们想要检索的内容,cypher会 自动解析语法并优化执行。
创建节点
CREATE (节点名:标签 {属性key1:属性value1,属性key2:属性value2,……})
1 | CREATE (p1:Person { name: "entere", age: 30, pid: 1 }) |
CREATE 创建数据
- () 表示节点 p1:Person,p1 是节点名( node ),Person 是 节点的标签名( lable )
- {} 是节点属性
要记住的事情: Neo4j的数据库服务器使用该<节点名称>以存储Database.As一个Neo4j的DBA或开发该节点的详细信息,我们不能用它来访问节点的详细信息。
Neo4j的数据库服务器创建一个<标签名称>作为别名到内部节点name.As一个Neo4j的DBA或开发人员,我们应该利用这个标签名称访问节点的详细信息。
创建关联
1 | match (p1),(p2) |
创建 p1 节点和 p2 节点的路径,此时变量 HAS_FANS 即代表关联,它也可以有标签 注意:创建关联之前须先创建节点,如果先创建关联,在创建节点会出问题
创建多个节点和关系
CREATE (节点1), (节点2), (节点3), (节点4), (节点1)-[关系1]->(节点2), (节点2)-[关系2]->(节点3),
查找案例一
1 | CREATE |
查询所有节点
1 | match (n) return n |
查询某个节点
1 | match (a:Person {name:”方兴东”})-[:HAS_FANS]->(b) return a,b |
统计节点个数
1 | match (a:Person {name:”方兴东”})-[:HAS_FANS]->(b) return count(b) |
查询任意关系
1 | match (a:Person {name:”方兴东”})-[*]->(b) return a,b |
按照属性值排序
1 | match (a:Person {name:”方兴东”})-[:HAS_FANS]->(b) return a,b order by b.uid desc |
查询属性name的值是方兴东的节点,及其所有关联节点
1 | match (a)-[r]->(b) where a.name=’方兴东’ return a,b |
查询属性name值是Kaine的节点,及其所有距离为1到3的关联节点
1 | match (a)-[1..3]->(b) where a.name=’方兴东’ return a,b |
查询属性name的值是方兴东的节点,及其所有距离为2并且去除距离为1的节点
在计算好友的好友时会用到,即如果a、b、c三个人都认识,如果仅计算跟a距离为2的人的时候会把b、c也算上,因为a->b->c,或者a->c->b都是通路)
1 | match (a)-[2]->(b) where a.name=’方兴东’ and not (a)-[1]->(b) return a,b |
查询方兴东和开心战士的共同粉丝
1 | MATCH (p1:Person {name:”方兴东”})-[:HAS_FANS]->(x)<-[:HAS_FANS]-(p2:Person {name:”开心战士”}) return x; |
注:关联的中括号内数字的含义
- n 距离为n
- ..n 最大距离为n
- n.. 最小距离为n
- m..n 距离在m到n之间
查询 方兴东 到 庄北 的最短路径
1 | match p = shortestPath( (p1:Person {name:”方兴东”})-[:HAS_FRIEND*..3]->(p2:Person {name:”庄北”}) ) return p; |
查找案例二
1 | create |
查询张三的直接朋友
1 | MATCH (p:User {name : “张三”})-[:HAS_FRIEND]->(f) return p,f; |
查询张三的朋友的朋友
1 | MATCH (p:User {name : “张三”})-[:HAS_FRIEND]->()-[:HAS_FRIEND]->(f) return p,f; |
查询张三所有的的朋友,包括朋友的朋友
1 | MATCH (p:User {name : “张三”})-[*]->(f) return p,f; |
查询张三到吴十的最短路径
1 | match p = shortestPath( (p3:User {name:”张三”})-[:HAS_FRIEND*..15]->(p10:User {name:”吴十”}) ) return p; |
索引
1 | :schema 列出所有标签的所有记录 |
清空
1 | match(n) |
Neo4j Spatial 简介
Neo4j Spatial概念
Neo4j Spatial项目是图数据库Neo4j的一个插件,它通过将空间数据映射到图模型(graph model),它将对象和关系当作顶点和边存储在图模型中。因而使得Neo4j具有空间数据的导入,存储,查询等功能。Neo4j Spatial支持的地理要素遵循OpenGIS的规范,包括点(point),线段(line-string),面(polygon),多点(multipoint),多线段(multi-linestring)等简单要素。Neo4j Spatial使用R树作为空间索引,主要是集成了Lucene 的索引库,支持的空间查询包括覆盖(cover),被覆盖(cover by),包含(contian),相交(intersect)等。一般而言,R树会将叶子结点(COUNT,LEVEL,
Neo4j Spatial特性
Neo4j Spatial的部分核心特性包括
- 支持Esri Shapefile格式,OSM(OpenStreetMap)格式(只支持.osm格式)(补充:Open Street Map目前逐步适用PBF替代OSM)
- 支持所有通用的几何要素
- 在空间查询的时候支持拓扑操作
- 允许任何图数据都实现空间操作功能
- 能够将单一图层或者数据集拆分成多个子图层
Neo4j Spatial 空间数据读取
地理图层与编码
Spatial 库中首先需要定义图层中几何要素,可供查询的索引,同时图层是否可编辑 ,其次是确定几何编码接口。Spatial类库提供的默认图层是标准图层,使用WKBGeometryEncoder,将所有的要素以字节数组的形式来存储。地理数据中实体的属性会当作图数据模型中顶点的属性来存储。OSMLayer 是支持Open Street Map格式的特殊图层,neo4j使用单个完全图来存储该图层。同时 OMSLayer继承动态图层,允许包含任意个子图层。
导入shapefile
导入shapefile大概过程是1.生存Neo4j数据库(调用已有) 2.实例化,并调用ShapefileImporter 3.关闭数据库 实例代码如下所示:
1 | package edu.sirc.gis.data; |
导入OSM
导入OSM的过程和导入shapefile差异不大,旧版Neo4j Spatial 提供了批量读入的接口BatchInserter,可以加快大文件的导入。具体JavaDoc请参阅打包后的文档。
1 | package edu.sirc.gis.data; |
Neo4j Server安装与配置
Neo4j Server 安装
Neo4j可以安装成数据库服务器,能够已应用或者系统服务两种形式运行在操作系统中。它内置了jetty 和REST接口,来实现使用浏览器对数据库操作
- 在neo4j官网http://neo4j.org/download下载你喜欢的版本(需要选择你的操作系统)
- 解压到特定位置,解压路径表述为$NEO4J_HOME(如/home/dev/neo4j/)
启动脚本在$NEO4J_HOME/bin 文件夹下,在Linux/MacOS下,运行 $NEO4J_HOME/bin/neo4j start 在Window 只要双击%NEO4J_HOME%\bin\Neo4j.bat文件即可
1
2cd $NEO4J_HOME/bin/
$NEO4J_HOME/bin/neo4j start
我们只需要访问 http://localhost:7474/webadmin/ 会出现Neo4j 的web 管理界面,如图1所示: 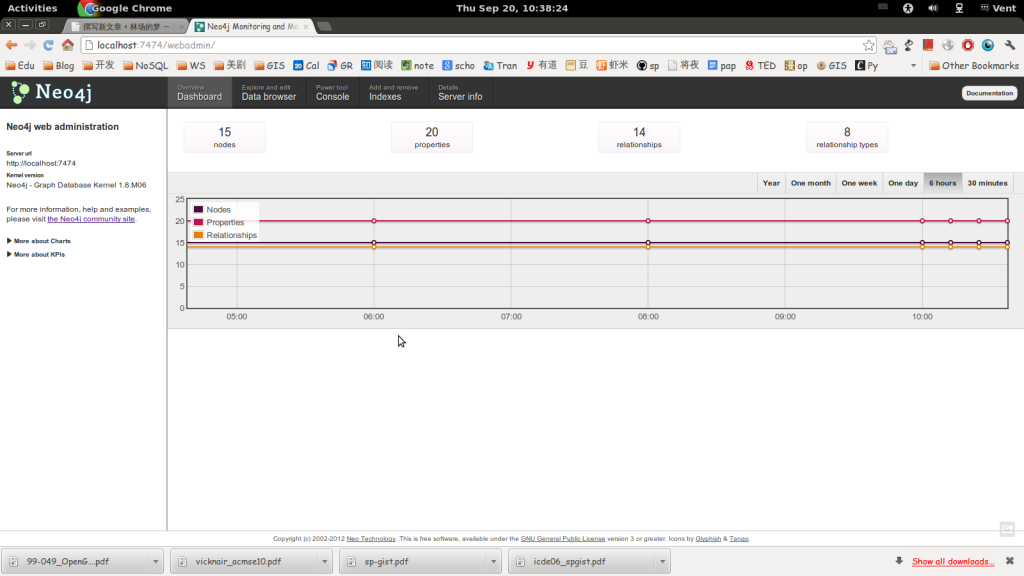
在Web 管理界面,我们可以查看数据库的节点,属性,关系信息。还可以通过Http ,Shell 和Germlin三种方式来对图数据库做CRUD。如果需要将Neo4j Server 以系统服务的方式运行
Neo4j Server 配置参数
如果我们需要对服务器的后端数据库性能调优等,可以通过Server的配置文件来了解图数据库的具体参数。这些重要的参数都存储在$NEO4J_HOME/conf/neo4j-server.properties文件内,包括服务器数据库在磁盘上的路径:
org.neo4j.server.database.location=data/graph.db http 服务器接口:
org.neo4j.server.database.location=data/graph.db 设置REST数据接口所能够操纵的数据库的相对路径
org.neo4j.server.webadmin.data.uri=/db/data/ 等。
至于Neo4j的性能参数和日志参数分别参看$NEO4J_HOME/conf/neo4j.properties,$NEO4J_HOME/conf/logging.properties两个文件。
Neo4j Server与Spatial集成
Neo4j Server的spatial插件安装
讲我们通过利用源码安装了neo4j spatial ,在/target目录下会有一个neo4j-spatial-0.9-SNAPSHOT-server-plugin.zip文件。如果没有,可以运行以下命令来获得该文件:
1 | git clone https://github.com/neo4j/spatial.git |
将该文件解压到,复制所有的jar包到neo4j 的lib文件夹内,然后重启neo4j server即可。
Neo4j Server的空间操作
索引新建
- Create a Spatial index
- Create nodes with lat/lon data as properties
- Add these nodes to the Spatial index
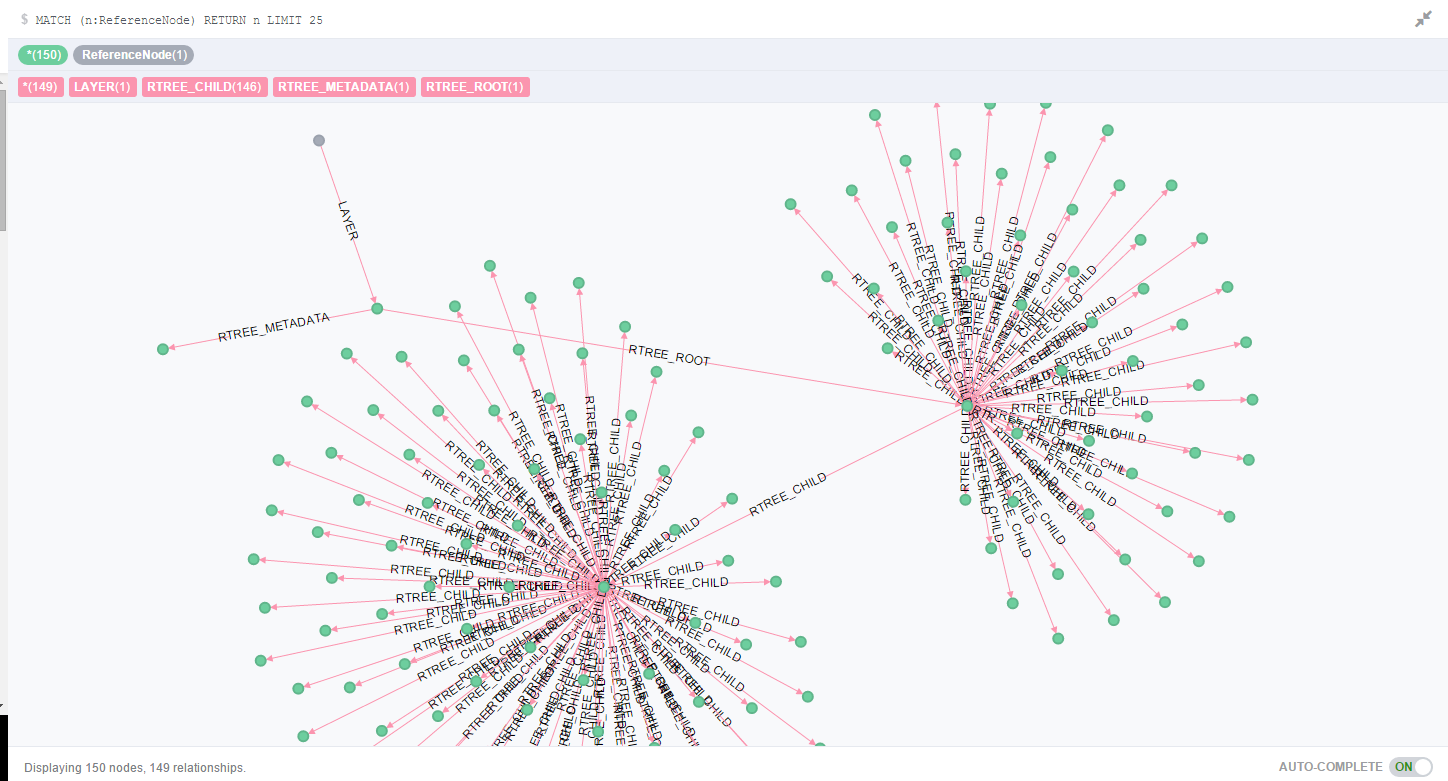
RTree关系可视化
关于withinDistance查询结果排序问题
球面距离计算采用OrthodromicDistance算法:d = acos( sin(lat1)_sin(lat2) + cos(lat1)_cos(lat2)_cos(lon2-lon1) )_ R,Neo4j-Spatial中的实现:org.neo4j.gis.spatial.pipes.processing.OrthodromicDistance
返回结果默认以命中目标坐标与查询中心点坐标的距离进行排序 参考Neo4j Spatial 源码测试用例中的:TestSimplePointLayer中的checkPointOrder, 查询示例:
1
List<geopipeflow> res = GeoPipeline. startNearestNeighborLatLonSearch( layer, start, distance).sort("OrthodromicDistance").toList();
neo4j spatial query 示例
withinDistance缓存区查询
查询点120.678966,31.300864周边0.1km范围内的Node
格式:START n = node:
1 | start n = node:geom('withinDistance:[31.331937,120.638154,0.1]') return n limit 10 |
bbox矩形查询
查询由点1(120.678966,31.300864)与点2(120.978966,31.330864)构成的BBox矩形范围内的Node
格式:START n = node:
1 | start n = node:geom('bbox:[120.678966,120.978966,31.300864,31.330864]') return n limit 10 |
withinWKTGeometry查询
查询由点1(120.678966,31.300864)与点2(120.978966,31.330864)构成的Polygon多边形范围内的Node
格式:START n = node:
1 | start n = node:geoindex('withinWKTGeometry:POLYGON ((120.678966 31.300864, 120.678966 31.330864, 120.978966 31.330864, 120.978966 31.300864, 120.678966 31.300864))') return n limit 10 |
空间索引和关系遍历联合查询
联合geom索引图层和match进行查询
- 查询指定范围&&指定path路径中的节点
1 | start n = node:geom('withinDistance:[31.331937,120.638154,0.1]') |
优化后
1 | profile start n = node:geom('withinDistance:[31.331937,120.638154,0.1]') |
查询结果可视化效果图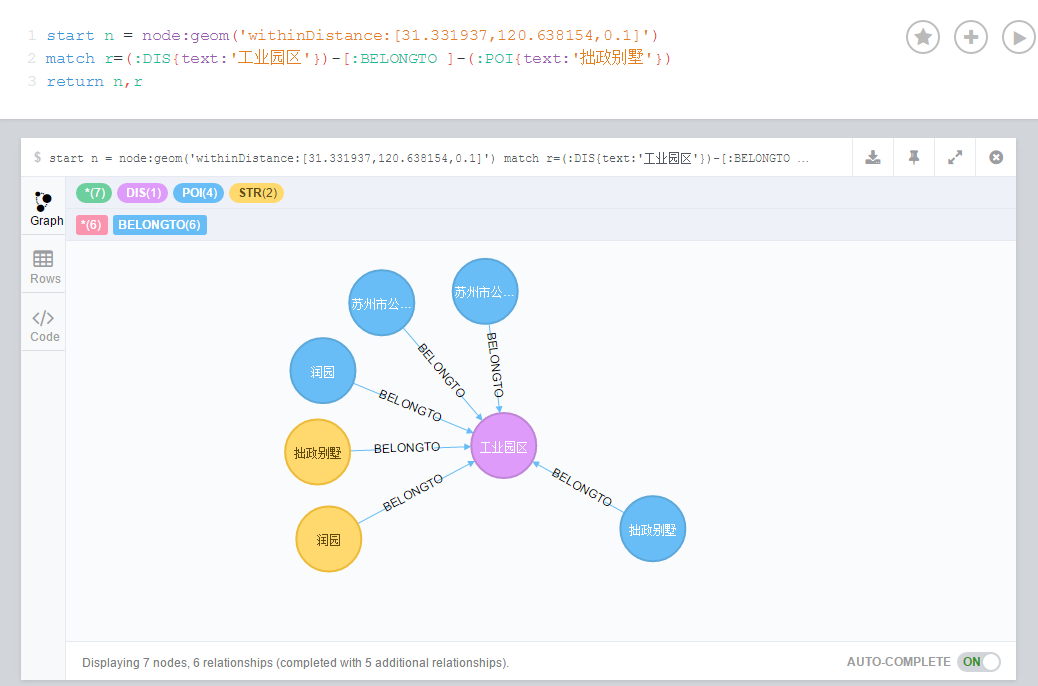
- 联合查询:withinWKTGeometry空间过滤与match属性过滤
1 | profile start n = node:geoindex('withinWKTGeometry:POLYGON ((120.678966 31.300864, 120.678966 31.330864, 120.978966 31.330864, 120.978966 31.300864, 120.678966 31.300864))') |
- CypherQL必须先执行空间索引,再执行Relation过滤,这样每个空间围内的Node都要进行Relationship过滤,效率较低;
- 若能先执行Match再执行空间过滤,可提高SpatialIndex命中率
- 若无分页需求,可临时采用NativeAPI进行Match过滤,再以SpatialIndex withinDiatance过滤。
- 若需要分页的话skip limit必须在CypherQL中实现,但是空间索引与关系遍历并行的CQL怎么写?暂时无解!
与GeoServer集成
GeoServer是一款基于java的开源的地图服务器,支持包括shapefile,postgis等多种数据源。neo4j spatial能够以插件的形式与GeoServer集成。集成方法如下:
解压neo4j-spatial-0.9-SNAPSHOT-server-plugin.zip,将里面除了gt-*_8.0的jar包 拷进geoserver/WEB-INF/lib 文件夹
复制neo4j/lib 里面所有jar 进入geoserver/WEB-INF/lib 文件夹
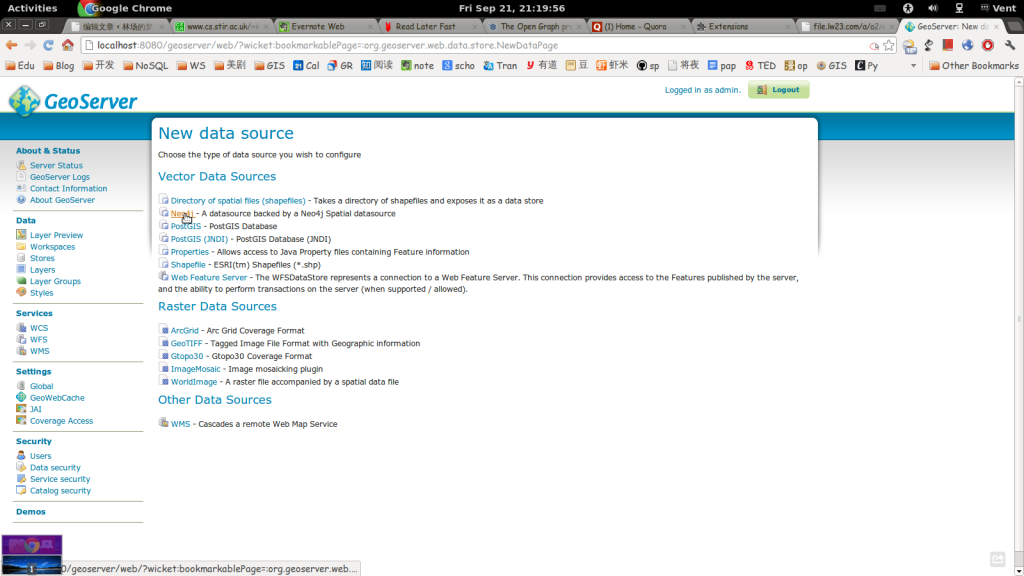
重启geoserver 通过访问GeoServer地址http://localhost:8080/geoserver/web/,我们可以看到如图所示,neo4j可以作为geoserver的后端,提供地图服务
问题
建空间索引内存溢出问题
neo4j transaction优化方案:每n条手动提交事物
1 | // 获取所有地址节类型,针对不同地址节分别构建R树索引 |
建空间索引速度还是偏慢,35万左右的数据量建索引花了将近1.5小时。