结合MongoDB开发LBS应用
文章目录
简介
随着近几年各类移动终端的迅速普及,基于地理位置的服务(LBS)和相关应用也越来越多,而支撑这些应用的最基础技术之一,就是基于地理位置信息的处理。
我将这些技术要点整理成文,希望能够通过本文的介绍和案例,详细解释如何使用MongoDB进行地理位置信息的查询和处理。在文章的开头,我也会先介绍一下业界通常用来处理地理位置信息的一些方案并进行比较,让读者逐步了解使用MongoDB查询及处理地理位置信息的优势。
LBS类应用特点
不管是什么LBS应用,一个共同的特点就是:他们的数据都或多或少包含了地理位置信息。而如何对这些信息进行查询、处理、分析,也就成为了支撑LBS应用的最基础也是最关键的技术问题。
而由于地理位置信息的特殊性,在开发中经常会有比较难以处理的问题出现,比如:由于用户所在位置的不固定性,用户可能会在很小范围内移动,而此时经纬度值也会随之变化;甚至在同一个位置,通过GPS设备获取到的位置信息也可能不一样。所以如果通过经纬度去获取周边信息时,就很难像传统数据库那样做查询并进行缓存。
对于这个问题,有读者可能会说有别的处理方案,没错,比如只按经纬度固定的几位小数点做索引,比如按矩阵将用户划分到某固定小范围的区域(可以参考后文将会提到的geohash)等方式,虽然可以绕个弯子解决,但或多或少操作起来比较麻烦,也会牺牲一些精度,甚至无法做到性能的最优化,所以不能算作是最佳的解决办法。
而最近几年,直接支持地理位置操作的数据库层出不穷,其操作友好、性能高的特性也开始被我们慢慢重视起来,其中的佼佼者当属MongoDB。
MongoDB在地理位置信息的处理上有什么优势?下面我们通过一个简单的案例来对比一下各种技术方案之间进行进行地理位置信息处理的差异。
几个地理位置信息处理方案的对比和分析
确定功能需求
对于任何LBS应用来说,让用户寻找周围的好友可能都是一个必不可少的功能,我们就以这个功能为例,来看看各种处理方案之间的差异和区别。
我们假设有如下功能需求:
- 显示我附近的人
- 由近到远排序
- 显示距离
可能的技术方案
排除一些不通用和难以实现的技术,我们罗列出以下几种方案:
- 基于MySQL数据库
- 采用GeoHash索引,基于MySQL
- MySQL空间存储(MySQL Spatial Extensions)
- 使用MongoDB存储地理位置信息
我们一个个来分析这几种方案
基于MySQL数据库
MySQL的使用非常简单。对于大部分已经使用MySQL的网站来说,使用这种方案没有任何迁移和部署成本。
而在MySQL中查询“最近的人”也仅需一条SQL即可,1
2
3SELECT id, ( 6371 * acos( cos( radians(37) ) * cos( radians( lat ) ) * cos( radians
( lng ) - radians(-122) ) + sin( radians(37) ) * sin( radians( lat ) ) ) ) AS distance
FROM places HAVING distance < 25 ORDER BY distance LIMIT 0 , 100;
注:这条SQL查询的是在lat,lng这个坐标附近的目标,并且按距离正序排列,SQL中的distance单位为公里。
但使用SQL语句进行查询的缺点也显而易见,每条SQL的计算量都会非常大,性能将会是严重的问题。
先别放弃,我们尝试对这条SQL做一些优化。
可以将圆形区域抽象为正方形,如下图: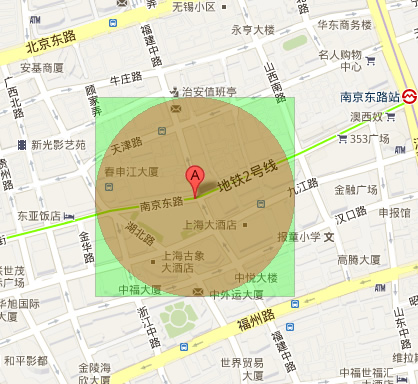
根据维基百科上的球面计算公式,可以根据圆心坐标计算出正方形四个点的坐标。
然后,查询这个正方形内的目标点。1
SELECT * FROM places WHERE ((lat BETWEEN ? AND ?) AND (lng BETWEEN ? AND ?))
这样优化后,虽然数据不完全精确,但性能提升很明显,并且可以通过给lat lng字段做索引的方式进一步加快这条SQL的查询速度。对精度有要求的应用也可以在这个结果上再进行计算,排除那些在方块范围内但不在原型范围内的数据,已达到对精度的要求。
可是这样查询出来的结果,是没有排序的,除非再进行一些SQL计算。但那又会在查询的过程中产生临时表排序,可能会造成性能问题。
GeoHash索引,基于MySQL
GeoHash是一种地址编码,通过切分地图区域为小方块(切分次数越多,精度越高),它能把二维的经纬度编码成一维的字符串。也就是说,理论上geohash字符串表示的并不是一个点,而是一个矩形区域,只要矩形区域足够小,达到所需精度即可。(其实MongoDB的索引也是基于geohash)
如:wtw3ued9m就是目前我所在的位置,降低一些精度,就会是wtw3ued,再降低一些精度,就会是wtw3u。(点击链接查看坐标编码对应Google地图的位置)
所以这样一来,我们就可以在MySQL中用LIKE ‘wtw3u%’来限定区域范围查询目标点,并且可以对结果集做缓存。更不会因为微小的经纬度变化而无法用上数据库的Query Cache。
这种方案的优点显而易见,仅用一个字符串保存经纬度信息,并且精度由字符串从头到尾的长度决定,可以方便索引。
但这种方案的缺点是:从geohash的编码算法中可以看出,靠近每个方块边界两侧的点虽然十分接近,但所属的编码会完全不同。实际应用中,虽然可以通过去搜索环绕当前方块周围的8个方块来解决该问题,但一下子将原来只需要1次SQL查询变成了需要查询9次,这样不仅增大了查询量,也将原本简单的方案复杂化了。
除此之外,这个方案也无法直接得到距离,需要程序协助进行后续的排序计算。
MySQL空间存储
MySQL的空间扩展(MySQL Spatial Extensions),它允许在MySQL中直接处理、保存和分析地理位置相关的信息,看起来这是使用MySQL处理地理位置信息的“官方解决方案”。但恰恰很可惜的是:它却不支持某些最基本的地理位置操作,比如查询在半径范围内的所有数据。它甚至连两坐标点之间的距离计算方法都没有(MySQL Spatial的distance方法在5.*版本中不支持)
官方指南的做法是这样的:1
GLength(LineStringFromWKB(LineString(point1, point2)))
这条语句的处理逻辑是先通过两个点产生一个LineString的类型的数据,然后调用GLength得到这个LineString的实际长度。
这么做虽然有些复杂,貌似也解决了距离计算的问题,但读者需要注意的是:这种方法计算的是欧式空间的距离,简单来说,它给出的结果是两个点在三维空间中的直线距离,不是飞机在地球上飞的那条轨迹,而是笔直穿过地球的那条直线。
所以如果你的地理位置信息是用经纬度进行存储的,你就无法简单的直接使用这种方式进行距离计算。
使用MongoDB存储地理位置信息
MongoDB原生支持地理位置索引,可以直接用于位置距离计算和查询。
另外,它也是如今最流行的NoSQL数据库之一,除了能够很好地支持地理位置计算之外,还拥有诸如面向集合存储、模式自由、高性能、支持复杂查询、支持完全索引等等特性。
对于我们的需求,在MongoDB只需一个命令即可得到所需要的结果:1
db.runCommand( { geoNear: "places", near: [ 121.4905, 31.2646 ], num:100 })
查询结果默认将会由近到远排序,而且查询结果也包含目标点对象、距离目标点的距离等信息。
由于geoNear是MongoDB原生支持的查询函数,所以性能上也做到了高度的优化,完全可以应付生产环境的压力。
方案总结
基于MongoDB做附近查询是很方便的一件事情。
MongoDB在地理位置信息方面的表现远远不限于此,它还支持更多更加方便的功能,如范围查询、距离自动计算等。
基于Mongodb的轨迹查询
由于轨迹是由开始位置和结束位置组成,而Mongodb的geoNear只支持一个Geo Index,因此通过一次查询并不能找到完整轨迹。因此采用workaround方式
- 对开始位置和结束位置分别建立geo index
- 利用near以及maxDistance来查询开始位置
- 利用near以及maxDistance来查询结束位置
- 通过解析开始位置查询获取_id
- 通过解析结束位置查询获取_id
- 因此满足要求的轨迹的_id一定同时出现在上述两个集合中