CANAL源码解析-store模块
文章目录
store模块简介
store模块用于binlog事件的存储 ,目前开源的版本中仅实现了Memory内存模式。官方文档中提到”后续计划增加本地file存储,mixed混合模式”,这句话大家不必当真,从笔者最开始接触canal到现在已经几年了,依然没有动静,好在Memory内存模式已经可以满足绝大部分场景。
store模块目录结构如下,该模块的核心接口为CanalEventStore:
以下是相关类图:
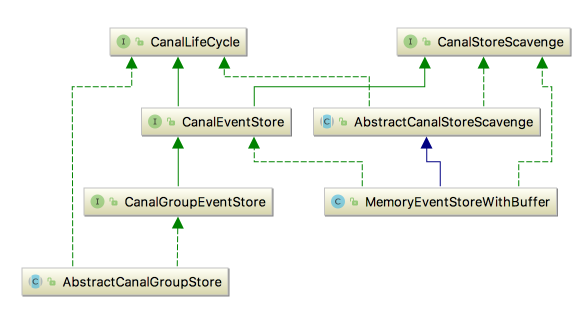
其中MemoryEventStoreWithBuffer就是内存模式的实现,是我们分析的重点,其实现了CanalEventStore接口,并继承了AbstractCanalStoreScavenge抽象类。需要注意的是,AbstractCanalStoreScavenge这个类中定义的字段和方法在开源版本中并没有任何地方使用到,因此我们不会对其进行分析。
MemoryEventStoreWithBuffer的实现借鉴了Disruptor的RingBuffer。简而言之,你可以把其当做一个环形队列,如下:
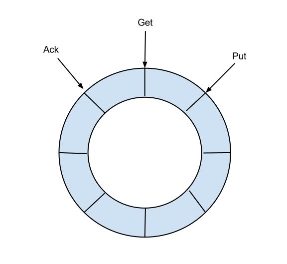
针对这个环形队列,canal定义了3类操作:Put、Get、Ack,其中:
- Put 操作: 添加数据。event parser模块拉取到binlog后,并经过event sink模块过滤,最终就通过Put操作存储到了队列中。
- Get操作: 获取数据。canal client连接到canal server后,最终获取到的binlog都是从这个队列中取得。
- Ack操作: 确认消费成功。canal client获取到binlog事件消费后,需要进行Ack。你可以认为Ack操作实际上就是将消费成功的事件从队列中删除,如果一直不Ack的话,队列满了之后,Put操作就无法添加新的数据了。
对应的,我们需要使用3个变量来记录Put、Get、Ack这三个操作的位置,其中:
- putSequence: 每放入一个数据putSequence +1,可表示存储数据存储的总数量
- getSequence: 每获取一个数据getSequence +1,可表示数据订阅获取的最后一次提取位置
- ackSequence: 每确认一个数据ackSequence + 1,可表示数据最后一次消费成功位置
另外,putSequence、getSequence、ackSequence这3个变量初始值都是-1,且都是递增的,均用long型表示。由于数据只有被Put进来后,才能进行Get;Get之后才能进行Ack。 所以,这三个变量满足以下关系:
1 | ackSequence <= getSequence <= putSequence |
如果将RingBuffer拉直来看,将会变得更加直观:
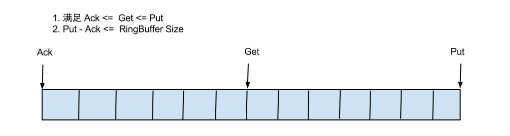
通过对这3个位置进行运算,我们可以得到一些有用的信息,如:
计算当前可消费的event数量:
1 | 当前可消费的event数量 = putSequence - getSequence |
计算当前队列的大小(即队列中还有多少事件等待消费):
1 | 当前队列的大小 = putSequence - ackSequence |
在进行Put/Get/Ack操作时,首先都要确定操作到环形队列的哪个位置。环形队列的bufferSize默认大小是16384,而这3个操作的位置变量putSequence、getSequence、ackSequence都是递增的,显然最终都会超过bufferSize。因此必须要对这3个值进行转换。最简单的操作就是使用%进行取余。
举例来说,putSequence的当前值为16383,这已经是环形队列的最大下标了(从0开始计算),下一个要插入的数据要在第16384个位置上,此时可以使用16384 % bufferSize = 0,因此下一个要插入的数据在0号位置上。可见,当达到队列的最大下标时,再从头开始循环,这也是为什么称之为环形队列的原因。当然在实际操作时,更加复杂,如0号位置上已经有数据了,就不能插入,需要等待这个位置被释放出来,否则出现数据覆盖。
canal使用的是通过位操作进行取余,这种取余方式与%作用完全相同,只不过因为是位操作,因此更加高效。其计算方式如下:
1 | 操作位置 = sequence & (bufferSize - 1) |
其中:
- canal.instance.memory.buffer.size: 表示RingBuffer队列的最大容量,也就是可缓存的binlog事件的最大记录数,其值需要为2的指数(原因如前所述,canal通过位运算进行取余),默认值为2^14=16384。
- canal.instance.memory.buffer.memunit: 表示RingBuffer使用的内存单元, 默认是1kb。和canal.instance.memory.buffer.size组合决定最终的内存使用大小。需要注意的是,这个配置项仅仅是用于计算占用总内存,并不是限制每个event最大为1kb。
- canal.instance.memory.batch.mode: 表示canal内存store中数据缓存模式,支持两种方式:
- ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量。这种方式有一些潜在的问题,举个极端例子,假设每个event有1M,那么16384个这种event占用内存要达到16G左右,基本上肯定会造成内存溢出(超大内存的物理机除外)。
- MEMSIZE : 根据buffer.size buffer.memunit的大小,限制缓存记录占用的总内存大小。指定为这种模式时,意味着默认缓存的event占用的总内存不能超过163841024=16M。这个值偏小,但笔者认为也足够了。因为通常我们在一个服务器上会部署多个instance,每个instance的store模块都会占用16M,因此只要instance的数量合适,也就不会浪费内存了。部分读者可能会担心,这是否限制了一个event的最大大小为16M,实际上是没有这个限制的。因为canal在Put一个新的event时,只会判断队列中已有的event占用的内存是否超过16M,如果没有,新的event不论大小是多少,总是可以放入的(canal的内存计算实际上是不精确的),之后的event再要放入时,如果这个超过16M的event没有被消费,则需要进行等待。
在canal自带的instance.xml文件中,使用了这些配置项来创建MemoryEventStoreWithBuffer实例,如下:
1 | <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer"> |
这里我们还看到了一个ddlIsolation属性,其对于Get操作生效,用于设置ddl语句是否单独一个batch返回(比如下游dml/ddl如果做batch内无序并发处理,会导致结构不一致)。其值通过canal.instance.get.ddl.isolation配置项来设置,默认值为false。
CanalEventStore接口
通过前面的分析,我们知道了环形队列要支持三种操作:Put、Get、Ack,针对这三种操作,在CanalEventStore中都有相应的方法定义,如下所示:
com.alibaba.otter.canal.store.CanalEventStore
1 | /** |
可以看到Put/Get/Ack操作都有多种重载形式,各个方法的作用参考方法注释即可,后文在分析MemoryEventStoreWithBuffer时,将会进行详细的介绍。
这里对 get方法返回的Events对象,进行一下说明:
com.alibaba.otter.canal.store.model.Events
1 | public class Events<EVENT> implements Serializable { |
可以看到,仅仅是通过一个List维护了一组数据,尽管这里定义的是泛型,但真实放入的数据实际上是Event类型。而PositionRange是protocol模块中的类,描述了这组Event的开始(start)和结束位置(end),显然,start表示List集合中第一个Event的位置,end表示最后一个Event的位置。
Event的定义如下所示 :
com.alibaba.otter.canal.store.model.Event
1 | public class Event implements Serializable { |
其中:CanalEntry.Entry和LogIdentity也都是protocol模块中的类:
- LogIdentity记录这个Event的来源信息mysql地址(sourceAddress)和slaveId。
- CanalEntry.Entry封装了binlog事件的数据
MemoryEventStoreWithBuffer
MemoryEventStoreWithBuffer是目前开源版本中的CanalEventStore接口的唯一实现,基于内存模式。当然你也可以进行扩展,提供一个基于本地文件存储方式的CanalEventStore实现。这样就可以一份数据让多个业务费进行订阅,只要独立维护消费位置元数据即可。然而,我不得不提醒你的是,基于本地文件的存储方式,一定要考虑好数据清理工作,否则会有大坑。
如果一个库只有一个业务方订阅,其实根本也不用实现本地存储,使用基于内存模式的队列进行缓存即可。如果client消费的快,那么队列中的数据放入后就被取走,队列基本上一直是空的,实现本地存储也没意义;如果client消费的慢,队列基本上一直是满的,只要client来获取,总是能拿到数据,因此也没有必要实现本地存储。
言归正传,下面对MemoryEventStoreWithBuffer的源码进行分析。
MemoryEventStoreWithBuffer字段
首先对MemoryEventStoreWithBuffer中定义的字段进行一下介绍,这是后面分析其他方法的基础,如下:
1 | public class MemoryEventStoreWithBuffer extends AbstractCanalStoreScavenge implements |
属性说明:
bufferSize、bufferMemUnit、batchMode、ddlIsolation、putSequence、getSequence、ackSequence:
这几个属性前面已经介绍过,这里不再赘述。
entries:
类型为Event[]数组,环形队列底层基于的Event[]数组,队列的大小就是bufferSize
indexMask
用于对putSequence、getSequence、ackSequence进行取余操作,前面已经介绍过canal通过位操作进行取余,其值为bufferSize-1 ,参见下文的start方法
putMemSize、getMemSize、ackMemSize:
分别用于记录put/get/ack操作的event占用内存的累加值,都是从0开始计算。例如每put一个event,putMemSize就要增加这个event占用的内存大小;get和ack操作也是类似。这三个变量,都是在batchMode指定为MEMSIZE的情况下,才会发生作用。
因为都是累加值,所以我们需要进行一些运算,才能得有有用的信息,如:
计算出当前环形队列当前占用的内存大小
1 | 环形队列当前占用的内存大小 = putMemSize - ackMemSize |
前面我们提到,batchMode为MEMSIZE时,需要限制环形队列中event占用的总内存,事实上在执行put操作前,就是通过这种方式计算出来当前大小,然后我们限制的bufferSize * bufferMemUnit大小进行比较。
1 | 尚未被获取的事件占用的内存大小 = putMemSize - getMemSize |
batchMode除了对PUT操作有限制,对Get操作也有影响。Get操作可以指定一个batchSize,用于指定批量获取的大小。当batchMode为MEMSIZE时,其含义就在不再是记录数,而是要获取到总共占用 batchSize * bufferMemUnit 内存大小的事件数量。
lock、notFull、notEmpty:
阻塞put/get操作控制信号。notFull用于控制put操作,只有队列没满的情况下才能put。notEmpty控制get操作,只有队列不为空的情况下,才能get。put操作和get操作共用一把锁(lock)。
启动和停止方法
MemoryEventStoreWithBuffer实现了CanalLifeCycle接口,因此实现了其定义的start、stop方法
start启动方法
start方法主要是初始化MemoryEventStoreWithBuffer内部的环形队列,其实就是初始化一下Event[]数组。
1 | public void start() throws CanalStoreException { |
stop停止方法
stop方法作用是停止,在停止时会清空所有缓存的数据,将维护的相关状态变量设置为初始值。
MemoryEventStoreWithBuffer#stop
1 | public void stop() throws CanalStoreException { |
在停止时,通过调用cleanAll方法清空所有缓存的数据。
cleanAll方法是在CanalStoreScavenge接口中定义的,在MemoryEventStoreWithBuffer中进行了实现, 此外这个接口还定义了另外一个方法cleanUtil,在执行ack操作时会被调用,我们将在介绍ack方法时进行讲解。
MemoryEventStoreWithBuffer#cleanAll
1 | public void cleanAll() throws CanalStoreException { |
Put操作
前面分析CanalEventStore接口中,我们看到总共有6个put方法,可以分为3类:
- 不带timeout超时参数的put方法,会一直进行阻塞,直到有足够的空间可以放入
- 带timeout参数超时参数的put方法,如果超过指定时间还未put成功,会抛出InterruptedException。
- tryPut方法每次只是尝试放入数据,立即返回true或者false,不会阻塞。
事实上,这些方法只是超时机制不同,底层都是通过调用doPut方法来完成真正的数据放入。因此在后面的分析中,笔者只选择其中一种进行讲解。
所有的put操作,在放入数据之前,都需要进行一些前置检查工作,主要检查2点:
检查是否足够的slot
默认的bufferSize设置大小为16384,即有16384个slot,每个slot可以存储一个event,因此canal默认最多缓存16384个event。从来另一个角度出发,这意味着putSequence最多比ackSequence可以大16384,不能超过这个值。如果超过了,就意味着尚未没有被消费的数据被覆盖了,相当于丢失了数据。因此,如果Put操作满足以下条件时,是不能新加入数据的1
(putSequence + need_put_events_size)- ackSequence > bufferSize
“putSequence + need_put_events_size”的结果为添加数据后的putSequence的最终位置值,要把这个作为预判断条件,其减去ackSequence,如果大于bufferSize,则不能插入数据。需要等待有足够的空间,或者抛出异常。
- 检测是否超出了内存限制
前面我们已经看到了,为了控制队列中event占用的总内存大小,可以指定batchMode为MEMSIZE。在这种情况下,buffer.size * buffer.memunit(默认为16M)就表示环形队列存储的event总共可以占用的内存大小。因此当出现以下情况下, 不能加入新的event:关于putMemSize和ackMemSize前面已经介绍过,二者的差值,实际上就是”队列当前包含的event占用的总内存”。1
(putMemSize - ackMemSize) > buffer.size * buffer.memunit
下面我们选择可以指定timeout超时时间的put方法进行讲解,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public boolean put(List<Event> data, long timeout, TimeUnit unit) throws InterruptedException,
CanalStoreException {
//1 如果需要插入的List为空,直接返回true
if (data == null || data.isEmpty()) {
return true;
}
//2 获得超时时间,并通过加锁进行put操作
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {//这是一个死循环,执行到下面任意一个return或者抛出异常是时才会停止
//3 检查是否满足插入条件,如果满足,进入到3.1,否则进入到3.2
if (checkFreeSlotAt(putSequence.get() + data.size())) {
//3.1 如果满足条件,调用doPut方法进行真正的插入
doPut(data);
return true;
}
//3.2 判断是否已经超时,如果超时,则不执行插入操作,直接返回false
if (nanos <= 0) {
return false;
}
//3.3 如果还没有超时,调用notFull.awaitNanos进行等待,需要其他线程调用notFull.signal()方法唤醒。
//唤醒是在ack操作中进行的,ack操作会删除已经消费成功的event,此时队列有了空间,因此可以唤醒,详见ack方法分析
//当被唤醒后,因为这是一个死循环,所以循环中的代码会重复执行。当插入条件满足时,调用doPut方法插入,然后返回
try {
nanos = notFull.awaitNanos(nanos);
//3.4 如果一直等待到超时,都没有可用空间可以插入,notFull.awaitNanos会抛出InterruptedException
} catch (InterruptedException ie) {
notFull.signal(); //3.5 超时之后,唤醒一个其他执行put操作且未被中断的线程(不明白是为了干啥)
throw ie;
}
}
} finally {
lock.unlock();
}
}
上述方法的第3步,通过调用checkFreeSlotAt方法来执行插入数据前的检查工作,所做的事情就是我们前面提到的2点:1、检查是否足够的slot 2、检测是否超出了内存限制,源码如下所示:
MemoryEventStoreWithBuffer#checkFreeSlotAt
1 | /**查询是否有空位*/ |
getMinimumGetOrAck方法用于返回getSequence和ackSequence二者的较小值,源码如下所示:
MemoryEventStoreWithBuffer#getMinimumGetOrAck
1 | private long getMinimumGetOrAck() { |
当checkFreeSlotAt方法检验通过后,最终调用的是doPut方法进行插入。doPut方法主要有4个步骤:
- 将新插入的event数据赋值到Event[]数组的正确位置上,就算完成了插入
- 当新插入的event记录数累加到putSequence上
- 累加新插入的event的大小到putMemSize上
- 调用notEmpty.signal()方法,通知队列中有数据了,如果之前有client获取数据处于阻塞状态,将会被唤醒
MemoryEventStoreWithBuffer#doPut
1 | /*** 执行具体的put操作*/ |
上述代码中,通过getIndex方法方法来进行位置转换,其内部通过位运算来快速取余数,不再赘述
MemoryEventStoreWithBuffer#getIndex
1 | private int getIndex(long sequcnce) { |
对于batchMode是MEMSIZE的情况下, 还会通过calculateSize方法计算每个event占用的内存大小,累加到putMemSize上。
MemoryEventStoreWithBuffer#calculateSize
1 | private long calculateSize(Event event) { |
其原理在于,mysql的binlog的event header中,都有一个event_length表示这个event占用的字节数。
parser模块将二进制形式binlog event解析后,这个event_length字段的值也被解析出来了,转换成Event对象后,在存储到store模块时,就可以根据其值判断占用内存大小。
需要注意的是,这个计算并不精确。原始的event_length表示的是event是二进制字节流时的字节数,在转换成java对象后,基本上都会变大。
Get操作
Put操作是canal parser模块解析binlog事件,并经过sink模块过滤后,放入到store模块中,也就是说Put操作实际上是canal内部调用。 Get操作(以及ack、rollback)则不同,其是由client发起的网络请求,server端通过对请求参数进行解析,最终调用CanalEventStore模块中定义的对应方法。
Get操作用于获取指定batchSize大小的Events。提供了3个方法:
1 | // 尝试获取,如果获取不到立即返回 |
其中:
- start参数:其类型为Posisiton,表示从哪个位置开始获取
- batchSize参数:表示批量获取的大小
- timeout和uint参数:超时参数配置
与Put操作类似,MemoryEventStoreWithBuffer在实现这三个方法时,真正的获取操作都是在doGet方法中进行的。这里我们依然只选择其中一种进行完整的讲解:
1 | public Events<Event> get(Position start, int batchSize, long timeout, TimeUnit unit) |
关于1.1步的描述”第一次订阅之后,需要包含一下start位置,防止丢失第一条记录”,这里进行一下特殊说明。首先要明确checkUnGetSlotAt方法的startPosition参数到底是从哪里传递过来的。
当一个client在获取数据时,CanalServerWithEmbedded的getWithoutAck/或get方法会被调用。其内部首先通过CanalMetaManager查找client的消费位置信息,由于是第一次,肯定没有记录,因此返回null,此时会调用CanalEventStore的getFirstPosition()方法,尝试把第一条数据作为消费的开始。而此时CanalEventStore中可能有数据,也可能没有数据。在没有数据的情况下,依然返回null;在有数据的情况下,把第一个Event的位置作为消费开始位置。那么显然,传入checkUnGetSlotAt方法的startPosition参数可能是null,也可能不是null。所以有了以下处理逻辑:
1 | if (startPosition == null || !startPosition.getPostion().isIncluded()) { |
如果不是null的情况下,尽管把第一个event当做开始位置,但是因为这个event毕竟还没有消费,所以在消费的时候我们必须也将其包含进去。之所以要+1,因为是第一次获取,getSequence的值肯定还是初始值-1,所以要+1变成0之后才是队列的第一个event位置。关于CanalEventStore的getFirstPosition()方法,我们将在最后分析。
当通过checkUnGetSlotAt的检查条件后,通过doGet方法进行真正的数据获取操作,获取主要分为5个步骤
- 确定从哪个位置开始获取数据
- 根据batchMode是MEMSIZE还是ITEMSIZE,通过不同的方式来获取数据
- 设置PositionRange,表示获取到的event列表开始和结束位置
- 设置ack点
- 累加getSequence,getMemSize值
MemoryEventStoreWithBuffer#doGet
1 | private Events<Event> doGet(Position start, int batchSize) throws CanalStoreException { |
补充说明:
- Get数据时,会通过isDdl方法判断event是否是ddl类型。
MemoryEventStoreWithBuffer#isDdl
1 | private boolean isDdl(EventType type) { |
这里的EventType是在protocol模块中定义的,并非mysql binlog event结构中的event type。在原始的mysql binlog event类型中,有一个QueryEvent,里面记录的是执行的sql语句,canal通过对这个sql语句进行正则表达式匹配,判断出这个event是否是DDL语句(参见SimpleDdlParser#parse方法)。
- 获取到event列表之后,会构造一个PostionRange对象。
通过CanalEventUtils.createPosition方法计算出第一、最后一个event的位置,作为PostionRange的开始和结束。
事实上,parser模块解析后,已经将位置信息:binlog文件,position封装到了Event中,createPosition方法只是将这些信息提取出来。
CanalEventUtils#createPosition
1 | public static LogPosition createPosition(Event event) { |
- 获取到Event列表后,会从中逆序寻找第一个类型为”事务开始/事务结束/DDL”的Event,将其位置作为PostionRange的可ack位置。
mysql原生的binlog事件中,总是以一个内容”BEGIN”的QueryEvent作为事务开始,以XidEvent事件表示事务结束。即使我们没有显式的开启事务,对于单独的一个更新语句(如Insert、update、delete),mysql也会默认开启事务。而canal将其转换成更容易理解的自定义EventType类型:TRANSACTIONBEGIN、TRANSACTIONEND。
而将这些事件作为ack点,主要是为了保证事务的完整性。例如client一次拉取了10个binlog event,前5个构成一个事务,后5个还不足以构成一个完整事务。在ack后,如果这个client停止了,也就是说下一个事务还没有被完整处理完。尽管之前ack的是10条数据,但是client重新启动后,将从第6个event开始消费,而不是从第11个event开始消费,因为第6个event是下一个事务的开始。
具体逻辑在于,canal server在接受到client ack后,CanalServerWithEmbedded#ack方法会执行。其内部首先根据ack的batchId找到对应的PositionRange,再找出其中的ack点,通过CanalMetaManager将这个位置记录下来。之后client重启后,再把这个位置信息取出来,从这个位置开始消费。
也就是说,ack位置实际上提供给CanalMetaManager使用的。而对于MemoryEventStoreWithBuffer本身而言,也需要进行ack,用于将已经消费的数据从队列中清除,从而腾出更多的空间存放新的数据。
ack操作
相对于get操作和put操作,ack操作没有重载,只有一个ack方法,用于清空指定position之前的数据,如下:
MemoryEventStoreWithBuffer#ack
1 | public void ack(Position position) throws CanalStoreException { |
CanalStoreScavenge接口定义了2个方法:cleanAll和cleanUntil。前面我们已经看到了在stop时,cleanAll方法会被执行。而每次ack时,cleanUntil方法会被执行,这个方法实现如下所示:
MemoryEventStoreWithBuffer#cleanUntil
1 | // postion表示要ack的配置 |
在匹配尚未ack的Event,是否有匹配的位置时,调用了CanalEventUtils#checkPosition方法。其内部:
- 首先比较Event的生成时间
- 接着,如果位置信息的binlog文件名或者信息不为空的话(通常不为空),则会进行精确匹配
CanalEventUtils#checkPosition
1 | /** |
rollback操作
相对于put/get/ack操作,rollback操作简单了很多。所谓rollback,就是client已经get到的数据,没能消费成功,因此需要进行回滚。回滚操作特别简单,只需要将getSequence的位置重置为ackSequence,将getMemSize设置为ackMemSize即可。
1 | public void rollback() throws CanalStoreException { |
其他方法
除了上述提到的所有方法外,MemoryEventStoreWithBuffer还提供了getFirstPosition()和getLatestPosition()方法,分别用于获取当前队列中的第一个和最后一个Event的位置信息。前面已经提到,在CanalServerWithEmbedded中会使用getFirstPosition()方法来获取CanalEventStore中存储的第一个Event的位置,而getLatestPosition()只是在一些单元测试中使用到,因此在这里我们只分析getFirstPosition()方法。
第一条数据通过ackSequence当前值对应的Event来确定,因为更早的Event在ack后都已经被删除了。相关源码如下:
MemoryEventStoreWithBuffer#getFirstPosition
1 | //获取第一条数据的position,如果没有数据返回为null |
代码逻辑很简单,唯一需要关注的是,通过CanalEventUtils#createPosition(Event, boolean)方法来计算第一个Event的位置,返回的是一个LogPosition对象。其中boolean参数用LogPosition内部维护的EntryPosition的included属性赋值。在前面get方法源码分析时,我们已经看到,当included值为false时,会把当前get位置+1,然后开始获取Event;当为true时,则直接从当前get位置开始获取数据。